一���、環(huán)境準備
CentOS Linux release 7.5.1804 (Core) 系統(tǒng)下
安裝
創(chuàng)建文件夾
$ cd /home/centos
$ mkdir software
$ mkdir module
將安裝包導入software文件夾
$ cd software
# 然后把文件拖進去即可
這里使用的安裝包是
/home/centos/software/hadoop-3.1.3.tar.gz
/home/centos/software/jdk-8u212-linux-x64.tar.gz
$ tar -zxvf jdk-8u212-linux-x64.tar.gz -C ../module
$ tar -zxvf hadoop-3.1.3.tar.gz -C ../module
配置環(huán)境變量
$ cd /etc/profile.d/
$ vim my_env.sh
為了不污染系統(tǒng)變量,我們自己創(chuàng)建一個環(huán)境變量的腳本���,配置內(nèi)容如下
#JAVA_HOME,PATH
# export 提升為全局變量,如果你的路徑和我不同�����,記得這里要使用自己的路徑哦
export JAVA_HOME=/home/centos/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
#HADOOP_HOME
export HADOOP_HOME=/home/centos/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
然后保存退出(這里不會的話可以看下vim基礎(chǔ)使用�����,不再贅述了)��。
我們source一下�����,使環(huán)境變量生效
測試一下,看看是否成功
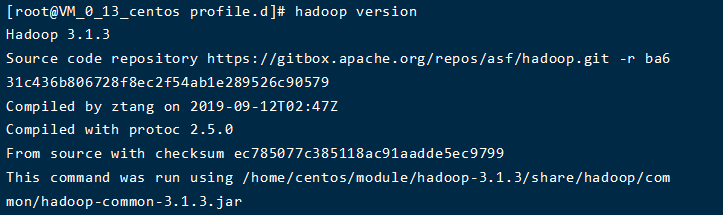
出現(xiàn)以上界面就是沒問題了���,如果還沒成功可以做以下兩項檢查:
- 去java和hadoop的安裝目錄下的bin目錄���,分別運行,看是否成功���。如果不成功��,說明安裝包解壓縮有問題�����,軟件本身就沒安裝成功。刪掉重新安裝�。
- 如果運行成功了�,說明是環(huán)境變量沒有配置成功�����。那么可以檢查一下環(huán)境變量的路徑設(shè)置,如果沒問題的話��,那重啟試試~
ssh免密
雖然是偽集群,但是本機連接本機的時候還是會需要密碼的���,所以要設(shè)置一下ssh免密
出現(xiàn)提示就不停的按回車即可�����,生成完秘鑰后
配置host文件
vi /etc/hosts
#這里我保留的配置為����,其中master配置的是騰訊云的內(nèi)網(wǎng)����, 如果配置外網(wǎng)會導致eclipse客戶端連不上hadoop
::1 localhost.localdomain localhost
::1 localhost6.localdomain6 localhost6
172.16.0.3 master
127.0.0.1 localhost
修改主機名
vi /etc/sysconfig/network
#修改HOSTNAME為master
HOSTNAME=master
修改hostname
$ hostnamectl --static set-hostname master
關(guān)閉防火墻
$ systemctl disable firewalld #永久
二、配置hadoop
配置文件
進入hadoop的配置文件專區(qū)����,所有配置文件都在這個文件夾
$ cd /home/centos/module/hadoop-3.1.3/etc/hadoop
我們要配置的文件主要有
core-site.xml
- fs.defaultFS是本機的訪問路徑���;
- hadoop.tmp.dir是數(shù)據(jù)的保存路徑
- 內(nèi)網(wǎng)地址不知道的去騰訊云網(wǎng)站上查一下
hdfs-site.xml
- dfs.replication是指數(shù)據(jù)的副本數(shù)���,默認是3
- 我們設(shè)置為1��,因為是偽集群嘛
yarn-site.xml
mapred-site.xml
hadoop-env.sh
- expert JAVA_HOME=你的jdk安裝路徑
那接下來就按照步驟操作吧��!
$ vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://騰訊云內(nèi)網(wǎng)ip地址:9820</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/centos/module/hadoop-3.1.3/data/tmp</value>
</property>
<!-- 通過web界面操作hdfs的權(quán)限 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 后面hive的兼容性配置 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
$ vim hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>騰訊云內(nèi)網(wǎng)ip地址:9868</value>
</property>
</configuration>
$ vim hadoop-env.sh
export JAVA_HOME=/home/centos/module/jdk1.8.0_212
$ vim yarn-site.xml
<configuration>
<!-- Reducer獲取數(shù)據(jù)的方式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<!-- 環(huán)境變量通過從NodeManagers的容器繼承的環(huán)境屬性�,對于mapreduce應(yīng)用程序��,除了默認值 hadoop op_mapred_home應(yīng)該被添加外。屬性值 還有如下-->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!-- 解決Yarn在執(zhí)行程序遇到超出虛擬內(nèi)存限制�����,Container被kill -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 后面hive的兼容性配置 -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<!-- 開啟日志聚集 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 訪問路徑-->
<property>
<name>yarn.log.server.url</name>
<value>http://172.17.0.13:19888/jobhistory/logs</value>
</property>
<!-- 保存的時間7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
配置歷史服務(wù)器
$ vim mapred-site.xml
<!-- 歷史服務(wù)器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>騰訊云內(nèi)網(wǎng)ip:10020</value>
</property>
<!-- 歷史服務(wù)器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>騰訊云內(nèi)網(wǎng)ip:19888</value>
</property>
初始化
第一次啟動需要格式化NameNode��,后面就不需要啦
初始化后�����,可以看到hadoop安裝文件夾中��,出現(xiàn)了data和logs兩個文件夾��,這樣就是初始化成功了
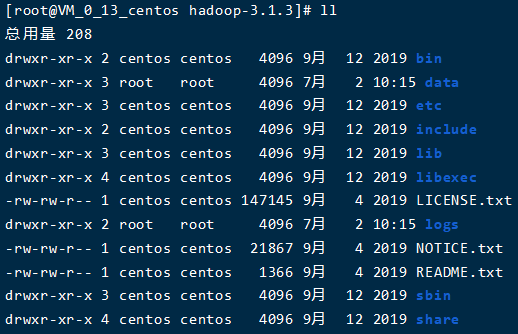
接下來看下啟動集群
啟動完畢���,沒有異常信息,查看一下進程
[root@VM_0_13_centos hadoop]# jps
20032 Jps
30900 DataNode
31355 SecondaryNameNode
30559 NameNode
全部啟動成功~��!
一鍵啟動
上面都沒問題后���,可以做一個腳本一鍵啟動集群��,在bin目錄下新建
添加如下內(nèi)容
#!/bin/bash
case $1 in
"start")
#dfs yarn history
start-dfs.sh
start-yarn.sh
mapred --daemon start historyserver
;;
"stop")
# dfs yarn history
stop-dfs.sh
stop-yarn.sh
mapred --daemon stop historyserver
;;
*)
echo "args is error! please input start or stop"
;;
esac
配置腳本的權(quán)限
使用腳本啟動
$ mycluster start
$ jps
23680 NodeManager
24129 JobHistoryServer
22417 DataNode
24420 Jps
22023 NameNode
23384 ResourceManager
22891 SecondaryNameNode
三��、查看hdfs
配置安全組規(guī)則
在進行以下操作前���,現(xiàn)在安全組規(guī)則中的協(xié)議端口中��,加入以下要使用的端口
端口號:
- Namenode ports: 9870
- Secondary NN ports: 9868
- JobHistory:19888
hadoop web頁面
在瀏覽器輸入:騰訊云公網(wǎng)地址:端口號�,即可進入對應(yīng)的web界面
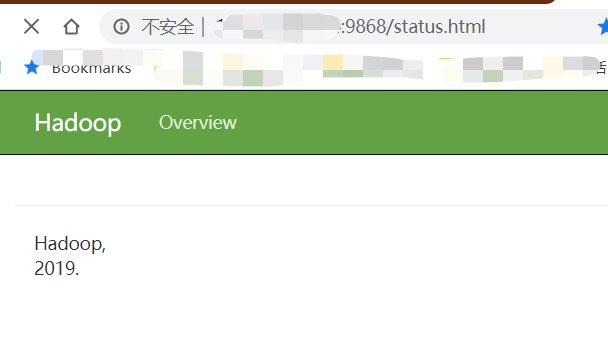
這是我們發(fā)現(xiàn)Secondary NameNode的界面顯示不太正常�,這是由于hadoop3中dfs-dust.js的時間函數(shù)使用有誤���。我們手動改正一下���。
首先關(guān)閉集群
修改文件
$ vim /home/centos/module/hadoop-3.1.3/share/hadoop/hdfs/webapps/static/dfs-dust.js
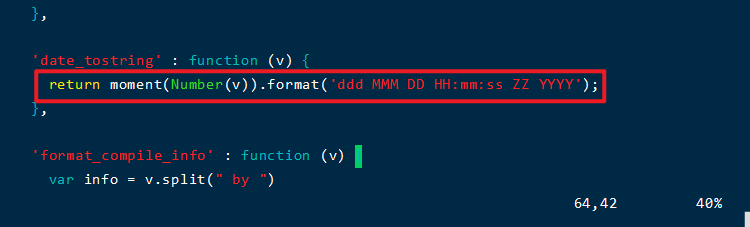
約61行的位置,如圖所示���,更改為:
return new Date(Number(v)).toLocaleString();
此時我們再啟動集群
可以看到Secondary NameNode的web界面已經(jīng)正常了

測試hdfs
那我們來上傳文件玩一玩吧
在hadoop目錄下新建一個文件夾
進入文件夾�,新建一個測試文件
內(nèi)容隨便寫吧,寫好保存���,我們開始上傳文件
$ hdfs dfs -put text.txt /
查看一下web頁面�,上傳成功了~
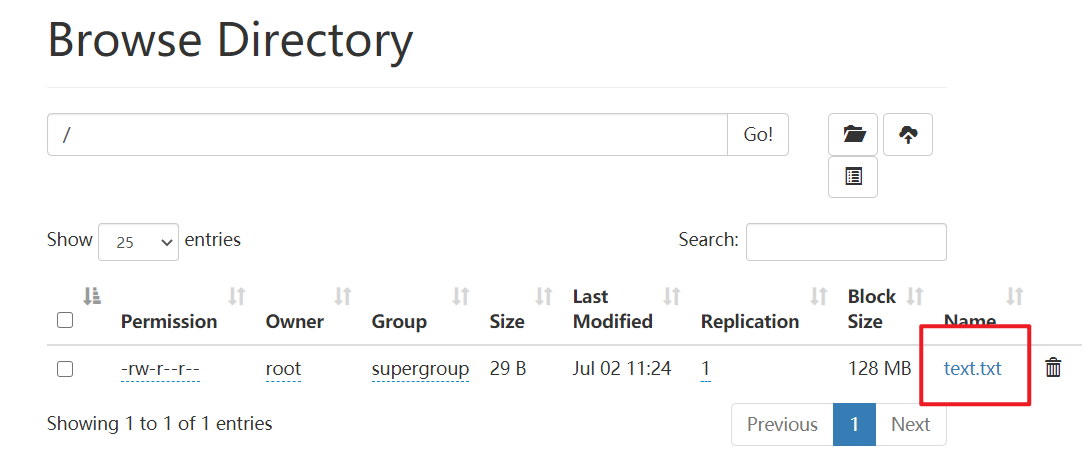
再嘗試把這個文件down下來
$ hdfs dfs -get /text.txt ./text1.txt
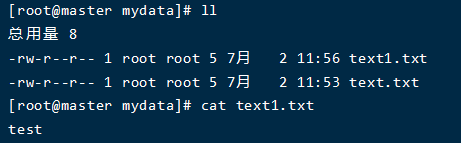
成功~
至此hadoop集群搭建完畢���,可以自己耍一些好玩的事啦~!
WordCount案例實操
在web端新建文件夾 input
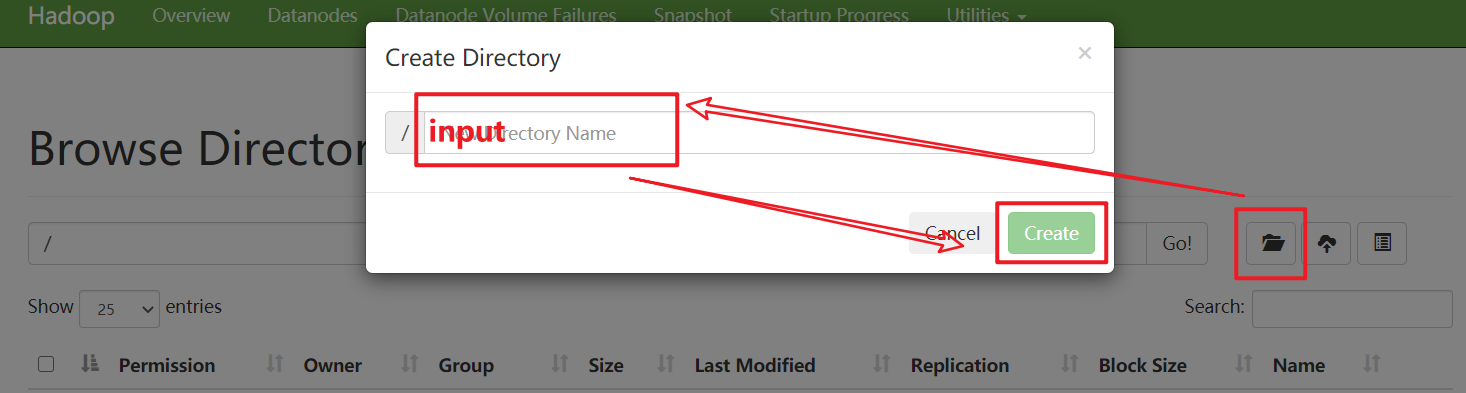
在其中上傳一個自己寫的各種單詞的文件���,做單詞統(tǒng)計
#或者自己在vim中寫好上傳也可
$ hdfs dfs -put wordcount.txt /input
然后測試一下wordcount案例,注意輸出文件夾不能存在
$ hadoop jar /home/centos/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output
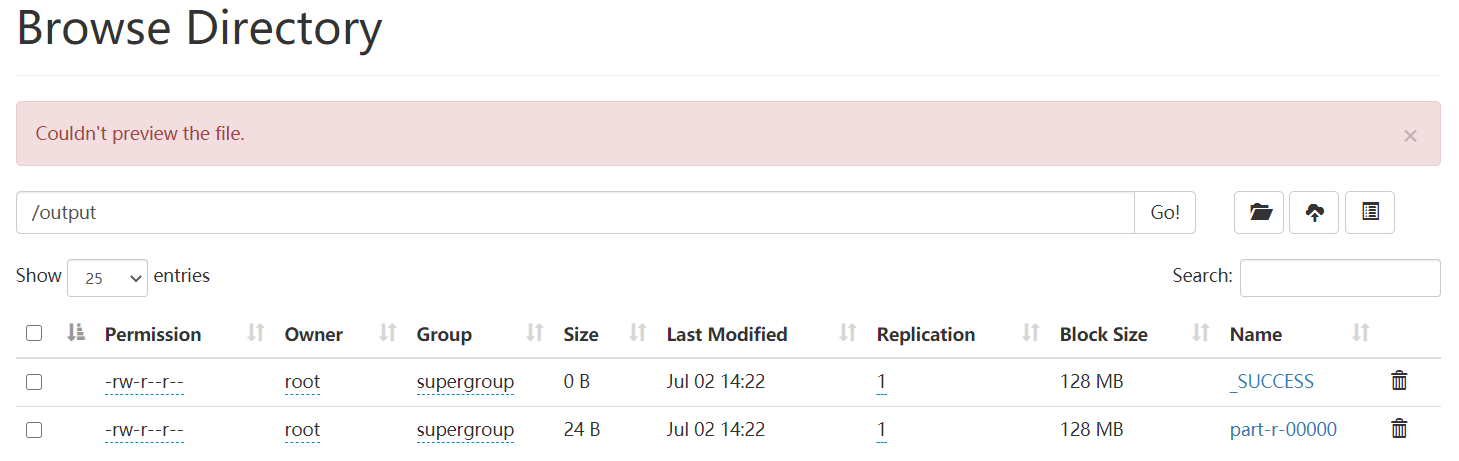
運行完之后,我們看一下結(jié)果
#拉取hdfs文件
[root@master mydata]# hdfs dfs -get /output ./
#查看結(jié)果
[root@master output]# cat part-r-00000
a 2
b 3
c 2
d 1
e 1
f 1
至此�,你已經(jīng)可以自由的玩耍hadoop啦�����。
當然,如果你已經(jīng)嘗試了的話����,會發(fā)現(xiàn),還有一個小問題沒有解決���,就是在web端點擊文件查看head或tail時��,會發(fā)生無法查看的情況�����,download也是不可以的���。這個在虛擬機安裝時并沒有發(fā)生過����,我還在研究怎么回事。如果有大神知道怎么回事����,可以留言說一下哈
到此這篇關(guān)于手把手教你在騰訊云上搭建hadoop3.x偽集群的方法的文章就介紹到這了,更多相關(guān)騰訊云搭建hadoop3.x偽集群內(nèi)容請搜索腳本之家以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持腳本之家��!

