目錄
- 使用范例
- 常用的對象–Tag
- 常用的對象–NavigableString
- 常用的對象–BeautifulSoup
- 常用的對象–Comment
- 對文檔樹的遍歷
- tag中包含多個字符串的情況
- .stripped_strings 去除空白內(nèi)容
- 搜索文檔樹–find和find_all
- select方法(各種查找)
- 獲取內(nèi)容
- 總結(jié)
使用范例
from bs4 import BeautifulSoup
#創(chuàng)建 Beautiful Soup 對象
# 使用lxml來進行解析
soup = BeautifulSoup(html,"lxml")
print(soup.prettify())
返回結(jié)果

常用的對象–Tag
就是 HTML 中的一個個標簽
在上面范例的基礎上添加
from bs4 import BeautifulSoup
#創(chuàng)建 Beautiful Soup 對象
# 使用lxml來進行解析
soup = BeautifulSoup(html,"lxml")
#print(soup.prettify())
#創(chuàng)建 Beautiful Soup 對象
soup = BeautifulSoup(html,'lxml')
print (soup.title)#None因為這里沒有tiele標簽所以返回none
print (soup.head)#None因為這里沒有head標簽所以返回none
print (soup.a)#返回 a class="fill-dec" target="_blank">編輯自我介紹,讓更多人了解你span class="write-icon">/span>/a>
print (type(soup.p))#返回 class 'bs4.element.Tag'>
print( soup.p)
其中print( soup.p)
返回結(jié)果為

同樣地�����,在上面地基礎上添加
print (soup.name)# [document] #soup 對象本身比較特殊�,它的 name 即為 [document]
返回
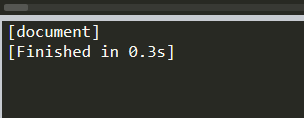
print (soup.head.name)#head #對于其他內(nèi)部標簽,輸出的值為標簽本身的名稱
print (soup.p.attrs)##把p標簽的所有屬性打印出來,得到的類型是一個字典。
返回
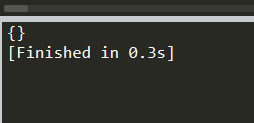
print (soup.p['class'])#獲取P標簽下地class標簽
soup.p['class'] = "newClass"
print (soup.p) # 可以對這些屬性和內(nèi)容等等進行修改
返回

常用的對象–NavigableString
前面地基礎上添加
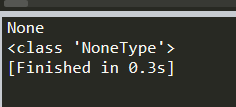
print (soup.p.string)
# The Dormouse's story
print (type(soup.p.string))
# class 'bs4.element.NavigableString'>thon
返回結(jié)果
常用的對象–BeautifulSoup
beautiful soup對象表示文檔的全部內(nèi)容����。大多數(shù)情況下,它可以被視為標記對象���。它支持遍歷文檔樹并搜索文檔樹中描述的大多數(shù)方法因為Beauty soup對象不是真正的HTML或XML標記�����,所以它沒有名稱和屬性���。但是,有時查看其內(nèi)容很方便���。Name屬性���,因此美麗的湯對象包含一個特殊屬性。值為“[文檔]”的名稱
print(soup.name)
#返回 '[document]'
常用的對象–Comment
用于解釋注釋部分的內(nèi)容
markup = "b>!--Hey, buddy. Want to buy a used parser?-->/b>"
soup = BeautifulSoup(markup)
comment = soup.b.string
type(comment)
# class 'bs4.element.Comment'>
對文檔樹的遍歷
在上面的基礎上添加
head_tag = soup.div
# 返回所有子節(jié)點的列表
print(head_tag.contents)
返回
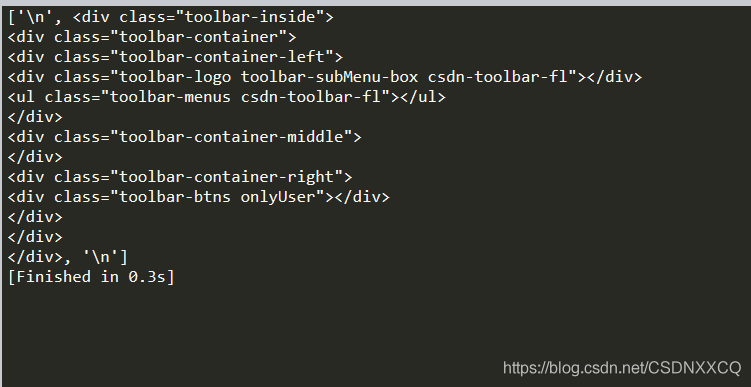
同理
head_tag = soup.div
# 返回所有子節(jié)點的迭代器
for child in head_tag.children:
print(child)
返回

tag中包含多個字符串的情況
可用 .strings 來循環(huán)獲取
for string in soup.strings:
print(repr(string))
返回
.stripped_strings 去除空白內(nèi)容
for string in soup.stripped_strings:
print(repr(string))
返回
搜索文檔樹–find和find_all
找到所有
print(soup.find_all("a",id='link2'))
find方法是找到第一個滿足條件的標簽后立即返回����,返回一個元素。find_all方法是把所有滿足條件的標簽都選到����,然后返回���。
select方法(各種查找)
#通過標簽名查找:
print(soup.select('a'))
#通過類名查找:
#通過類名,則應該在類的前面加一個'.'
print(soup.select('.sister'))
#通過id查找:
#通過id查找��,應該在id的名字前面加一個#號
print(soup.select("#link1"))
查找a標簽返回的結(jié)果

其他因為網(wǎng)頁本身沒有�����,返回的是一個空列表
組合查找
print(soup.select("p #link1"))#查找 p 標簽中����,id 等于 link1的內(nèi)容
子標簽查找
print(soup.select("head > title"))
通過屬性查找
print(soup.select('a[))#屬性與標簽屬同一節(jié)點,中間不能有空格
獲取內(nèi)容
先查看類型
print (type(soup.select('div')))

for title in soup.select('div'):
print (title.get_text())
返回

print (soup.select('div')[20].get_text())#選取第20個div標簽的內(nèi)容
返回

總結(jié)
本篇文章就到這里了��,希望能給你帶來幫助��,也希望您能夠多多關注腳本之家的更多內(nèi)容!
您可能感興趣的文章:- Python BeautifulSoup基本用法詳解(通過標簽及class定位元素)
- python beautiful soup庫入門安裝教程
- Python爬蟲進階之Beautiful Soup庫詳解
- python爬蟲beautifulsoup庫使用操作教程全解(python爬蟲基礎入門)
- python網(wǎng)絡爬蟲精解之Beautiful Soup的使用說明

