最近在工作中碰到了 GC 的問題:項目中大量重復地創(chuàng)建許多對象,造成 GC 的工作量巨大,CPU 頻繁掉底���。準備使用 sync.Pool 來緩存對象���,減輕 GC 的消耗���。為了用起來更順暢,我特地研究了一番�����,形成此文�����。本文從使用到源碼解析�����,循序漸進����,一一道來���。
是什么
sync.Pool 是 sync 包下的一個組件,可以作為保存臨時取還對象的一個“池子”。個人覺得它的名字有一定的誤導性�����,因為 Pool 里裝的對象可以被無通知地被回收��,可能 sync.Cache 是一個更合適的名字。
有什么用
對于很多需要重復分配、回收內(nèi)存的地方��,sync.Pool 是一個很好的選擇。頻繁地分配、回收內(nèi)存會給 GC 帶來一定的負擔,嚴重的時候會引起 CPU 的毛刺�,而 sync.Pool 可以將暫時不用的對象緩存起來�����,待下次需要的時候直接使用,不用再次經(jīng)過內(nèi)存分配�,復用對象的內(nèi)存,減輕 GC 的壓力���,提升系統(tǒng)的性能。
怎么用
首先���,sync.Pool 是協(xié)程安全的�����,這對于使用者來說是極其方便的�。使用前�����,設(shè)置好對象的 New 函數(shù)���,用于在 Pool 里沒有緩存的對象時����,創(chuàng)建一個。之后�,在程序的任何地方、任何時候僅通過 Get()���、Put() 方法就可以取�、還對象了����。
下面是 2018 年的時候,《Go 夜讀》上關(guān)于 sync.Pool 的分享����,關(guān)于適用場景:
當多個 goroutine 都需要創(chuàng)建同⼀個對象的時候,如果 goroutine 數(shù)過多�����,導致對象的創(chuàng)建數(shù)⽬劇增���,進⽽導致 GC 壓⼒增大��。形成 “并發(fā)⼤-占⽤內(nèi)存⼤-GC 緩慢-處理并發(fā)能⼒降低-并發(fā)更⼤”這樣的惡性循環(huán)��。
在這個時候���,需要有⼀個對象池��,每個 goroutine 不再⾃⼰單獨創(chuàng)建對象����,⽽是從對象池中獲取出⼀個對象(如果池中已經(jīng)有的話)����。
因此關(guān)鍵思想就是對象的復用���,避免重復創(chuàng)建�、銷毀��,下面我們來看看如何使用�。
簡單的例子
首先來看一個簡單的例子:
package main
import (
"fmt"
"sync"
)
var pool *sync.Pool
type Person struct {
Name string
}
func initPool() {
pool = sync.Pool {
New: func()interface{} {
fmt.Println("Creating a new Person")
return new(Person)
},
}
}
func main() {
initPool()
p := pool.Get().(*Person)
fmt.Println("首次從 pool 里獲取:", p)
p.Name = "first"
fmt.Printf("設(shè)置 p.Name = %s\n", p.Name)
pool.Put(p)
fmt.Println("Pool 里已有一個對象:{first}�����,調(diào)用 Get: ", pool.Get().(*Person))
fmt.Println("Pool 沒有對象了��,調(diào)用 Get: ", pool.Get().(*Person))
}
運行結(jié)果:
Creating a new Person
首次從 pool 里獲取: {}
設(shè)置 p.Name = first
Pool 里已有一個對象:{first}�����,Get: {first}
Creating a new Person
Pool 沒有對象了�,Get: {}
首先,需要初始化 Pool�,唯一需要的就是設(shè)置好 New 函數(shù)。當調(diào)用 Get 方法時����,如果池子里緩存了對象,就直接返回緩存的對象���。如果沒有存貨���,則調(diào)用 New 函數(shù)創(chuàng)建一個新的對象。
另外��,我們發(fā)現(xiàn) Get 方法取出來的對象和上次 Put 進去的對象實際上是同一個����,Pool 沒有做任何“清空”的處理。但我們不應當對此有任何假設(shè)��,因為在實際的并發(fā)使用場景中,無法保證這種順序���,最好的做法是在 Put 前���,將對象清空。
fmt 包如何用
這部分主要看 fmt.Printf 如何使用:
func Printf(format string, a ...interface{}) (n int, err error) {
return Fprintf(os.Stdout, format, a...)
}
繼續(xù)看 Fprintf:
func Fprintf(w io.Writer, format string, a ...interface{}) (n int, err error) {
p := newPrinter()
p.doPrintf(format, a)
n, err = w.Write(p.buf)
p.free()
return
}
Fprintf 函數(shù)的參數(shù)是一個 io.Writer���,Printf 傳的是 os.Stdout��,相當于直接輸出到標準輸出�����。這里的 newPrinter 用的就是 Pool:
// newPrinter allocates a new pp struct or grabs a cached one.
func newPrinter() *pp {
p := ppFree.Get().(*pp)
p.panicking = false
p.erroring = false
p.wrapErrs = false
p.fmt.init(p.buf)
return p
}
var ppFree = sync.Pool{
New: func() interface{} { return new(pp) },
}
回到 Fprintf 函數(shù),拿到 pp 指針后�,會做一些 format 的操作,并且將 p.buf 里面的內(nèi)容寫入 w��。最后����,調(diào)用 free 函數(shù),將 pp 指針歸還到 Pool 中:
// free saves used pp structs in ppFree; avoids an allocation per invocation.
func (p *pp) free() {
if cap(p.buf) > 6410 {
return
}
p.buf = p.buf[:0]
p.arg = nil
p.value = reflect.Value{}
p.wrappedErr = nil
ppFree.Put(p)
}
歸還到 Pool 前將對象的一些字段清零�,這樣,通過 Get 拿到緩存的對象時,就可以安全地使用了�����。
pool_test
通過 test 文件學習源碼是一個很好的途徑����,因為它代表了“官方”的用法。更重要的是��,測試用例會故意測試一些“坑”��,學習這些坑�,也會讓自己在使用的時候就能學會避免。
pool_test 文件里共有 7 個測試����,4 個 BechMark。
TestPool 和 TestPoolNew 比較簡單��,主要是測試 Get/Put 的功能��。我們來看下 TestPoolNew:
func TestPoolNew(t *testing.T) {
// disable GC so we can control when it happens.
defer debug.SetGCPercent(debug.SetGCPercent(-1))
i := 0
p := Pool{
New: func() interface{} {
i++
return i
},
}
if v := p.Get(); v != 1 {
t.Fatalf("got %v; want 1", v)
}
if v := p.Get(); v != 2 {
t.Fatalf("got %v; want 2", v)
}
// Make sure that the goroutine doesn't migrate to another P
// between Put and Get calls.
Runtime_procPin()
p.Put(42)
if v := p.Get(); v != 42 {
t.Fatalf("got %v; want 42", v)
}
Runtime_procUnpin()
if v := p.Get(); v != 3 {
t.Fatalf("got %v; want 3", v)
}
}
首先設(shè)置了 GC=-1��,作用就是停止 GC�。那為啥要用 defer����?函數(shù)都跑完了�,還要 defer 干啥。注意到���,debug.SetGCPercent 這個函數(shù)被調(diào)用了兩次����,而且這個函數(shù)返回的是上一次 GC 的值�。因此,defer 在這里的用途是還原到調(diào)用此函數(shù)之前的 GC 設(shè)置�,也就是恢復現(xiàn)場。
接著����,調(diào)置了 Pool 的 New 函數(shù):直接返回一個 int,變且每次調(diào)用 New��,都會自增 1��。然后���,連續(xù)調(diào)用了兩次 Get 函數(shù)�,因為這個時候 Pool 里沒有緩存的對象�,因此每次都會調(diào)用 New 創(chuàng)建一個,所以第一次返回 1���,第二次返回 2�����。
然后�����,調(diào)用 Runtime_procPin() 防止 goroutine 被強占���,目的是保護接下來的一次 Put 和 Get 操作,使得它們操作的對象都是同一個 P 的“池子”�。并且,這次調(diào)用 Get 的時候并沒有調(diào)用 New���,因為之前有一次 Put 的操作����。
最后�,再次調(diào)用 Get 操作��,因為沒有“存貨”���,因此還是會再次調(diào)用 New 創(chuàng)建一個對象。
TestPoolGC 和 TestPoolRelease 則主要測試 GC 對 Pool 里對象的影響�����。這里用了一個函數(shù)����,用于計數(shù)有多少對象會被 GC 回收:
runtime.SetFinalizer(v, func(vv *string) {
atomic.AddUint32(fin, 1)
})
當垃圾回收檢測到 v 是一個不可達的對象時,并且 v 又有一個關(guān)聯(lián)的 Finalizer��,就會另起一個 goroutine 調(diào)用設(shè)置的 finalizer 函數(shù)��,也就是上面代碼里的參數(shù) func�。這樣,就會讓對象 v 重新可達�����,從而在這次 GC 過程中不被回收����。之后,解綁對象 v 和它所關(guān)聯(lián)的 Finalizer�,當下次 GC 再次檢測到對象 v 不可達時,才會被回收��。
TestPoolStress 從名字看���,主要是想測一下“壓力”���,具體操作就是起了 10 個 goroutine 不斷地向 Pool 里 Put 對象,然后又 Get 對象����,看是否會出錯。
TestPoolDequeue 和 TestPoolChain�����,都調(diào)用了 testPoolDequeue�,這是具體干活的。它需要傳入一個 PoolDequeue 接口:
// poolDequeue testing.
type PoolDequeue interface {
PushHead(val interface{}) bool
PopHead() (interface{}, bool)
PopTail() (interface{}, bool)
}
PoolDequeue 是一個雙端隊列�����,可以從頭部入隊元素��,從頭部和尾部出隊元素。調(diào)用函數(shù)時���,前者傳入 NewPoolDequeue(16)�����,后者傳入 NewPoolChain()����,底層其實都是 poolDequeue 這個結(jié)構(gòu)體���。具體來看 testPoolDequeue 做了什么:
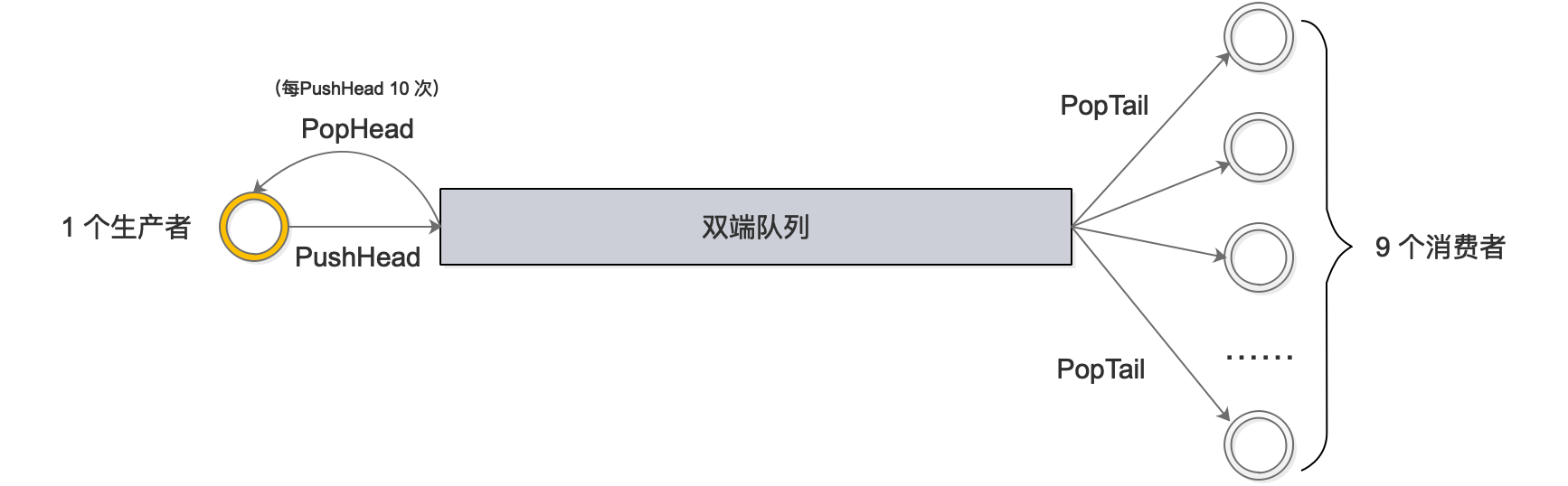
總共起了 10 個 goroutine:1 個生產(chǎn)者�����,9 個消費者�。生產(chǎn)者不斷地從隊列頭 pushHead 元素到雙端隊列里去�,并且每 push 10 次,就 popHead 一次�;消費者則一直從隊列尾取元素。不論是從隊列頭還是從隊列尾取元素�����,都會在 map 里做標記,最后檢驗每個元素是不是只被取出過一次��。
剩下的就是 Benchmark 測試了��。第一個 BenchmarkPool 比較簡單����,就是不停地 Put/Get��,測試性能��。
BenchmarkPoolSTW 函數(shù)會先關(guān)掉 GC�,再向 pool 里 put 10 個對象,然后強制觸發(fā) GC���,記錄 GC 的停頓時間����,并且做一個排序���,計算 P50 和 P95 的 STW 時間���。這個函數(shù)可以加入個人的代碼庫了:
func BenchmarkPoolSTW(b *testing.B) {
// Take control of GC.
defer debug.SetGCPercent(debug.SetGCPercent(-1))
var mstats runtime.MemStats
var pauses []uint64
var p Pool
for i := 0; i b.N; i++ {
// Put a large number of items into a pool.
const N = 100000
var item interface{} = 42
for i := 0; i N; i++ {
p.Put(item)
}
// Do a GC.
runtime.GC()
// Record pause time.
runtime.ReadMemStats(mstats)
pauses = append(pauses, mstats.PauseNs[(mstats.NumGC+255)%256])
}
// Get pause time stats.
sort.Slice(pauses, func(i, j int) bool { return pauses[i] pauses[j] })
var total uint64
for _, ns := range pauses {
total += ns
}
// ns/op for this benchmark is average STW time.
b.ReportMetric(float64(total)/float64(b.N), "ns/op")
b.ReportMetric(float64(pauses[len(pauses)*95/100]), "p95-ns/STW")
b.ReportMetric(float64(pauses[len(pauses)*50/100]), "p50-ns/STW")
}
我在 mac 上跑了一下:
go test -v -run=none -bench=BenchmarkPoolSTW
得到輸出:
goos: darwin
goarch: amd64
pkg: sync
BenchmarkPoolSTW-12 361 3708 ns/op 3583 p50-ns/STW 5008 p95-ns/STW
PASS
ok sync 1.481s
最后一個 BenchmarkPoolExpensiveNew 測試當 New 的代價很高時�����,Pool 的表現(xiàn)�。也可以加入個人的代碼庫����。
其他
標準庫中 encoding/json 也用到了 sync.Pool 來提升性能。著名的 gin 框架�����,對 context 取用也到了 sync.Pool���。
來看下 gin 如何使用 sync.Pool���。設(shè)置 New 函數(shù):
engine.pool.New = func() interface{} {
return engine.allocateContext()
}
func (engine *Engine) allocateContext() *Context {
return Context{engine: engine, KeysMutex: sync.RWMutex{}}
}
使用:
// ServeHTTP conforms to the http.Handler interface.
func (engine *Engine) ServeHTTP(w http.ResponseWriter, req *http.Request) {
c := engine.pool.Get().(*Context)
c.writermem.reset(w)
c.Request = req
c.reset()
engine.handleHTTPRequest(c)
engine.pool.Put(c)
}
先調(diào)用 Get 取出來緩存的對象,然后會做一些 reset 操作����,再執(zhí)行 handleHTTPRequest,最后再 Put 回 Pool���。
另外���,Echo 框架也使⽤了 sync.Pool 來管理 context�,并且⼏乎達到了零堆內(nèi)存分配:
It leverages sync pool to reuse memory and achieve zero dynamic memory allocation with no GC overhead.
源碼分析
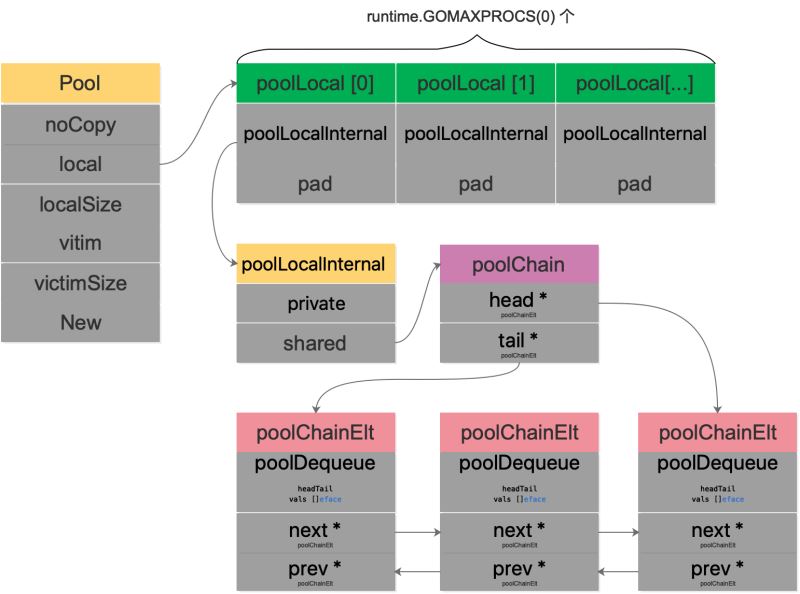
Pool 結(jié)構(gòu)體
首先來看 Pool 的結(jié)構(gòu)體:
type Pool struct {
noCopy noCopy
// 每個 P 的本地隊列����,實際類型為 [P]poolLocal
local unsafe.Pointer // local fixed-size per-P pool, actual type is [P]poolLocal
// [P]poolLocal的大小
localSize uintptr // size of the local array
victim unsafe.Pointer // local from previous cycle
victimSize uintptr // size of victims array
// 自定義的對象創(chuàng)建回調(diào)函數(shù)�����,當 pool 中無可用對象時會調(diào)用此函數(shù)
New func() interface{}
}
因為 Pool 不希望被復制�,所以結(jié)構(gòu)體里有一個 noCopy 的字段,使用 go vet 工具可以檢測到用戶代碼是否復制了 Pool��。
noCopy 是 go1.7 開始引入的一個靜態(tài)檢查機制�����。它不僅僅工作在運行時或標準庫���,同時也對用戶代碼有效���。
用戶只需實現(xiàn)這樣的不消耗內(nèi)存、僅用于靜態(tài)分析的結(jié)構(gòu),來保證一個對象在第一次使用后不會發(fā)生復制�����。
實現(xiàn)非常簡單:
// noCopy 用于嵌入一個結(jié)構(gòu)體中來保證其第一次使用后不會被復制
//
// 見 https://golang.org/issues/8005#issuecomment-190753527
type noCopy struct{}
// Lock 是一個空操作用來給 `go ve` 的 -copylocks 靜態(tài)分析
func (*noCopy) Lock() {}
func (*noCopy) Unlock() {}
local 字段存儲指向 [P]poolLocal 數(shù)組(嚴格來說��,它是一個切片)的指針����,localSize 則表示 local 數(shù)組的大小。訪問時����,P 的 id 對應 [P]poolLocal 下標索引。通過這樣的設(shè)計�����,多個 goroutine 使用同一個 Pool 時�,減少了競爭,提升了性能�。
在一輪 GC 到來時,victim 和 victimSize 會分別“接管” local 和 localSize�。victim 的機制用于減少 GC 后冷啟動導致的性能抖動,讓分配對象更平滑���。
Victim Cache 本來是計算機架構(gòu)里面的一個概念�,是 CPU 硬件處理緩存的一種技術(shù),sync.Pool 引入的意圖在于降低 GC 壓力的同時提高命中率��。
當 Pool 沒有緩存的對象時���,調(diào)用 New 方法生成一個新的對象�。
type poolLocal struct {
poolLocalInternal
// 將 poolLocal 補齊至兩個緩存行的倍數(shù)�,防止 false sharing,
// 每個緩存行具有 64 bytes,即 512 bit
// 目前我們的處理器一般擁有 32 * 1024 / 64 = 512 條緩存行
// 偽共享�,僅占位用�,防止在 cache line 上分配多個 poolLocalInternal
pad [128 - unsafe.Sizeof(poolLocalInternal{})%128]byte
}
// Local per-P Pool appendix.
type poolLocalInternal struct {
// P 的私有緩存區(qū),使用時無需要加鎖
private interface{}
// 公共緩存區(qū)�����。本地 P 可以 pushHead/popHead�;其他 P 則只能 popTail
shared poolChain
}
字段 pad 主要是防止 false sharing,董大的《什么是 cpu cache》里講得比較好:
現(xiàn)代 cpu 中��,cache 都劃分成以 cache line (cache block) 為單位�,在 x86_64 體系下一般都是 64 字節(jié),cache line 是操作的最小單元����。
程序即使只想讀內(nèi)存中的 1 個字節(jié)數(shù)據(jù)����,也要同時把附近 63 節(jié)字加載到 cache 中��,如果讀取超個 64 字節(jié)��,那么就要加載到多個 cache line 中�����。
簡單來說��,如果沒有 pad 字段���,那么當需要訪問 0 號索引的 poolLocal 時���,CPU 同時會把 0 號和 1 號索引同時加載到 cpu cache。在只修改 0 號索引的情況下����,會讓 1 號索引的 poolLocal 失效。這樣�,當其他線程想要讀取 1 號索引時�����,發(fā)生 cache miss��,還得重新再加載����,對性能有損�。增加一個 pad,補齊緩存行�����,讓相關(guān)的字段能獨立地加載到緩存行就不會出現(xiàn) false sharding 了�����。
poolChain 是一個雙端隊列的實現(xiàn):
type poolChain struct {
// 只有生產(chǎn)者會 push to�,不用加鎖
head *poolChainElt
// 讀寫需要原子控制��。 pop from
tail *poolChainElt
}
type poolChainElt struct {
poolDequeue
// next 被 producer 寫�,consumer 讀。所以只會從 nil 變成 non-nil
// prev 被 consumer 寫��,producer 讀。所以只會從 non-nil 變成 nil
next, prev *poolChainElt
}
type poolDequeue struct {
// The head index is stored in the most-significant bits so
// that we can atomically add to it and the overflow is
// harmless.
// headTail 包含一個 32 位的 head 和一個 32 位的 tail 指針�����。這兩個值都和 len(vals)-1 取模過��。
// tail 是隊列中最老的數(shù)據(jù)�,head 指向下一個將要填充的 slot
// slots 的有效范圍是 [tail, head),由 consumers 持有�����。
headTail uint64
// vals 是一個存儲 interface{} 的環(huán)形隊列�����,它的 size 必須是 2 的冪
// 如果 slot 為空�����,則 vals[i].typ 為空���;否則���,非空�。
// 一個 slot 在這時宣告無效:tail 不指向它了����,vals[i].typ 為 nil
// 由 consumer 設(shè)置成 nil,由 producer 讀
vals []eface
}
poolDequeue 被實現(xiàn)為單生產(chǎn)者����、多消費者的固定大小的無鎖(atomic 實現(xiàn)) Ring 式隊列(底層存儲使用數(shù)組,使用兩個指針標記 head���、tail)���。生產(chǎn)者可以從 head 插入、head 刪除�,而消費者僅可從 tail 刪除。
headTail 指向隊列的頭和尾����,通過位運算將 head 和 tail 存入 headTail 變量中。
我們用一幅圖來完整地描述 Pool 結(jié)構(gòu)體:
結(jié)合木白的技術(shù)私廚的《請問sync.Pool有什么缺點?》里的一張圖����,對于雙端隊列的理解會更容易一些:
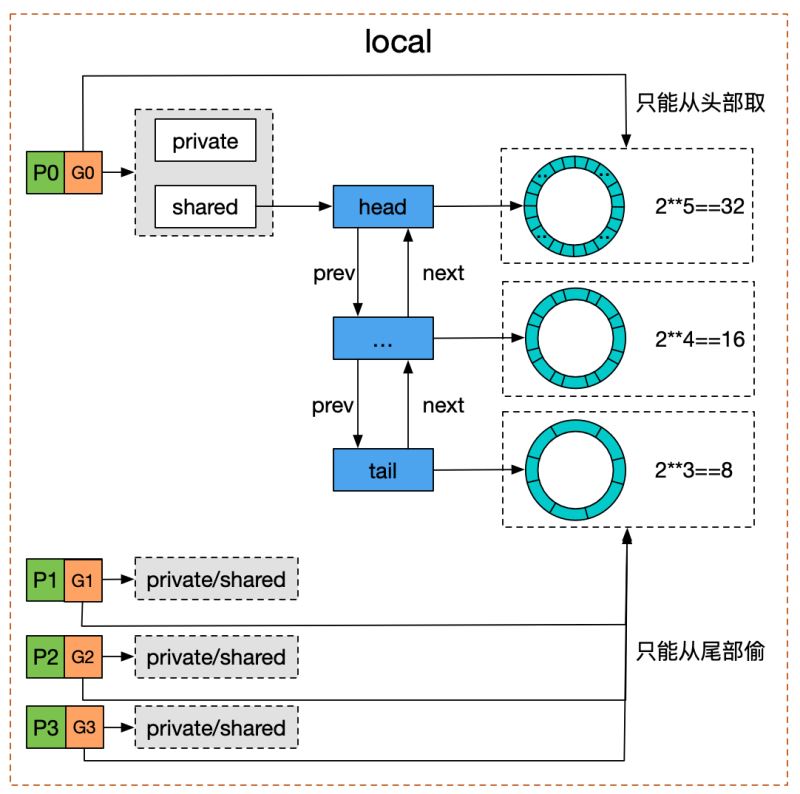
我們看到 Pool 并沒有直接使用 poolDequeue�����,原因是它的大小是固定的,而 Pool 的大小是沒有限制的���。因此�����,在 poolDequeue 之上包裝了一下��,變成了一個 poolChainElt 的雙向鏈表���,可以動態(tài)增長。
Get
直接上源碼:
func (p *Pool) Get() interface{} {
// ......
l, pid := p.pin()
x := l.private
l.private = nil
if x == nil {
x, _ = l.shared.popHead()
if x == nil {
x = p.getSlow(pid)
}
}
runtime_procUnpin()
// ......
if x == nil p.New != nil {
x = p.New()
}
return x
}
省略號的內(nèi)容是 race 相關(guān)的�,屬于閱讀源碼過程中的一些噪音,暫時注釋掉�。這樣,Get 的整個過程就非常清晰了:
- 首先��,調(diào)用
p.pin() 函數(shù)將當前的 goroutine 和 P 綁定����,禁止被搶占,返回當前 P 對應的 poolLocal,以及 pid�。
- 然后直接取 l.private,賦值給 x�,并置 l.private 為 nil。
- 判斷 x 是否為空�����,若為空���,則嘗試從 l.shared 的頭部 pop 一個對象出來����,同時賦值給 x�����。
- 如果 x 仍然為空��,則調(diào)用 getSlow 嘗試從其他 P 的 shared 雙端隊列尾部“偷”一個對象出來��。
- Pool 的相關(guān)操作做完了����,調(diào)用
runtime_procUnpin() 解除非搶占��。
- 最后如果還是沒有取到緩存的對象,那就直接調(diào)用預先設(shè)置好的 New 函數(shù)���,創(chuàng)建一個出來���。
我用一張流程圖來展示整個過程:

整體流程梳理完了,我們再來看一下其中的一些關(guān)鍵函數(shù)�。
pin
先來看 Pool.pin():
// src/sync/pool.go
// 調(diào)用方必須在完成取值后調(diào)用 runtime_procUnpin() 來取消搶占。
func (p *Pool) pin() (*poolLocal, int) {
pid := runtime_procPin()
s := atomic.LoadUintptr(p.localSize) // load-acquire
l := p.local // load-consume
// 因為可能存在動態(tài)的 P(運行時調(diào)整 P 的個數(shù))
if uintptr(pid) s {
return indexLocal(l, pid), pid
}
return p.pinSlow()
}
pin 的作用就是將當前 groutine 和 P 綁定在一起�����,禁止搶占�����。并且返回對應的 poolLocal 以及 P 的 id����。
如果 G 被搶占,則 G 的狀態(tài)從 running 變成 runnable��,會被放回 P 的 localq 或 globaq�,等待下一次調(diào)度���。下次再執(zhí)行時,就不一定是和現(xiàn)在的 P 相結(jié)合了��。因為之后會用到 pid��,如果被搶占了���,有可能接下來使用的 pid 與所綁定的 P 并非同一個�。
“綁定”的任務最終交給了 procPin:
// src/runtime/proc.go
func procPin() int {
_g_ := getg()
mp := _g_.m
mp.locks++
return int(mp.p.ptr().id)
}
實現(xiàn)的代碼很簡潔:將當前 goroutine 綁定的 m 上的一個鎖字段 locks 值加 1��,即完成了“綁定”�。關(guān)于 pin 的原理,可以參考《golang的對象池sync.pool源碼解讀》��,文章詳細分析了為什么執(zhí)行 procPin 之后��,不可搶占�����,且 GC 不會清掃 Pool 里的對象��。
我們再回到 p.pin()���,原子操作取出 p.localSize 和 p.local���,如果當前 pid 小于 p.localSize��,則直接取 poolLocal 數(shù)組中的 pid 索引處的元素。否則����,說明 Pool 還沒有創(chuàng)建 poolLocal,調(diào)用 p.pinSlow() 完成創(chuàng)建工作���。
func (p *Pool) pinSlow() (*poolLocal, int) {
// Retry under the mutex.
// Can not lock the mutex while pinned.
runtime_procUnpin()
allPoolsMu.Lock()
defer allPoolsMu.Unlock()
pid := runtime_procPin()
// poolCleanup won't be called while we are pinned.
// 沒有使用原子操作����,因為已經(jīng)加了全局鎖了
s := p.localSize
l := p.local
// 因為 pinSlow 中途可能已經(jīng)被其他的線程調(diào)用�,因此這時候需要再次對 pid 進行檢查。 如果 pid 在 p.local 大小范圍內(nèi)���,則不用創(chuàng)建 poolLocal 切片�����,直接返回�。
if uintptr(pid) s {
return indexLocal(l, pid), pid
}
if p.local == nil {
allPools = append(allPools, p)
}
// If GOMAXPROCS changes between GCs, we re-allocate the array and lose the old one.
// 當前 P 的數(shù)量
size := runtime.GOMAXPROCS(0)
local := make([]poolLocal, size)
// 舊的 local 會被回收
atomic.StorePointer(p.local, unsafe.Pointer(local[0])) // store-release
atomic.StoreUintptr(p.localSize, uintptr(size)) // store-release
return local[pid], pid
}
因為要上一把大鎖 allPoolsMu,所以函數(shù)名帶有 slow���。我們知道����,鎖粒度越大�,競爭越多,自然就越“slow”�����。不過要想上鎖的話��,得先解除“綁定”�����,鎖上之后��,再執(zhí)行“綁定”�。原因是鎖越大,被阻塞的概率就越大�,如果還占著 P,那就浪費資源�����。
在解除綁定后,pinSlow 可能被其他的線程調(diào)用過了�,p.local 可能會發(fā)生變化。因此這時候需要再次對 pid 進行檢查���。如果 pid 在 p.localSize 大小范圍內(nèi)��,則不用再創(chuàng)建 poolLocal 切片,直接返回����。
之后,根據(jù) P 的個數(shù)�,使用 make 創(chuàng)建切片,包含 runtime.GOMAXPROCS(0) 個 poolLocal���,并且使用原子操作設(shè)置 p.local 和 p.localSize��。
最后����,返回 p.local 對應 pid 索引處的元素���。
關(guān)于這把大鎖 allPoolsMu��,曹大在《幾個 Go 系統(tǒng)可能遇到的鎖問題》里講了一個例子��。第三方庫用了 sync.Pool���,內(nèi)部有一個結(jié)構(gòu)體 fasttemplate.Template����,包含 sync.Pool 字段����。而 rd 在使用時,每個請求都會新建這樣一個結(jié)構(gòu)體��。于是��,處理每個請求時�����,都會嘗試從一個空的 Pool 里取緩存的對象����,最后 goroutine 都阻塞在了這把大鎖上���,因為都在嘗試執(zhí)行:allPools = append(allPools, p),從而造成性能問題��。
popHead
回到 Get 函數(shù)�,再來看另一個關(guān)鍵的函數(shù):poolChain.popHead():
func (c *poolChain) popHead() (interface{}, bool) {
d := c.head
for d != nil {
if val, ok := d.popHead(); ok {
return val, ok
}
// There may still be unconsumed elements in the
// previous dequeue, so try backing up.
d = loadPoolChainElt(d.prev)
}
return nil, false
}
popHead 函數(shù)只會被 producer 調(diào)用。首先拿到頭節(jié)點:c.head�����,如果頭節(jié)點不為空的話��,嘗試調(diào)用頭節(jié)點的 popHead 方法��。注意這兩個 popHead 方法實際上并不相同��,一個是 poolChain 的�����,一個是 poolDequeue 的�,有疑惑的���,不妨回頭再看一下 Pool 結(jié)構(gòu)體的圖��。我們來看 poolDequeue.popHead():
// /usr/local/go/src/sync/poolqueue.go
func (d *poolDequeue) popHead() (interface{}, bool) {
var slot *eface
for {
ptrs := atomic.LoadUint64(d.headTail)
head, tail := d.unpack(ptrs)
// 判斷隊列是否為空
if tail == head {
// Queue is empty.
return nil, false
}
// head 位置是隊頭的前一個位置���,所以此處要先退一位����。
// 在讀出 slot 的 value 之前就把 head 值減 1���,取消對這個 slot 的控制
head--
ptrs2 := d.pack(head, tail)
if atomic.CompareAndSwapUint64(d.headTail, ptrs, ptrs2) {
// We successfully took back slot.
slot = d.vals[headuint32(len(d.vals)-1)]
break
}
}
// 取出 val
val := *(*interface{})(unsafe.Pointer(slot))
if val == dequeueNil(nil) {
val = nil
}
// 重置 slot���,typ 和 val 均為 nil
// 這里清空的方式與 popTail 不同,與 pushHead 沒有競爭關(guān)系��,所以不用太小心
*slot = eface{}
return val, true
}
此函數(shù)會刪掉并且返回 queue 的頭節(jié)點��。但如果 queue 為空的話�,返回 false。這里的 queue 存儲的實際上就是 Pool 里緩存的對象����。
整個函數(shù)的核心是一個無限循環(huán),這是 Go 中常用的無鎖化編程形式���。
首先調(diào)用 unpack 函數(shù)分離出 head 和 tail 指針���,如果 head 和 tail 相等�,即首尾相等���,那么這個隊列就是空的�,直接就返回 nil��,false��。
否則��,將 head 指針后移一位�����,即 head 值減 1���,然后調(diào)用 pack 打包 head 和 tail 指針。使用 atomic.CompareAndSwapUint64 比較 headTail 在這之間是否有變化����,如果沒變化,相當于獲取到了這把鎖,那就更新 headTail 的值�����。并且把 vals 相應索引處的元素賦值給 slot��。
因為 vals 長度實際是只能是 2 的 n 次冪�,因此 len(d.vals)-1 實際上得到的值的低 n 位是全 1,它再與 head 相與�����,實際就是取 head 低 n 位的值�。
得到相應 slot 的元素后,經(jīng)過類型轉(zhuǎn)換并判斷是否是 dequeueNil�����,如果是���,說明沒取到緩存的對象�,返回 nil����。
// /usr/local/go/src/sync/poolqueue.go
// 因為使用 nil 代表空的 slots�����,因此使用 dequeueNil 表示 interface{}(nil)
type dequeueNil *struct{}
最后���,返回 val 之前,將 slot “歸零”:*slot = eface{}��。
回到 poolChain.popHead()���,調(diào)用 poolDequeue.popHead() 拿到緩存的對象后����,直接返回���。否則�����,將 d 重新指向 d.prev�����,繼續(xù)嘗試獲取緩存的對象��。
getSlow
如果在 shared 里沒有獲取到緩存對象��,則繼續(xù)調(diào)用 Pool.getSlow()�,嘗試從其他 P 的 poolLocal 偷?�。?/p>
func (p *Pool) getSlow(pid int) interface{} {
// See the comment in pin regarding ordering of the loads.
size := atomic.LoadUintptr(p.localSize) // load-acquire
locals := p.local // load-consume
// Try to steal one element from other procs.
// 從其他 P 中竊取對象
for i := 0; i int(size); i++ {
l := indexLocal(locals, (pid+i+1)%int(size))
if x, _ := l.shared.popTail(); x != nil {
return x
}
}
// 嘗試從victim cache中取對象�����。這發(fā)生在嘗試從其他 P 的 poolLocal 偷去失敗后�����,
// 因為這樣可以使 victim 中的對象更容易被回收���。
size = atomic.LoadUintptr(p.victimSize)
if uintptr(pid) >= size {
return nil
}
locals = p.victim
l := indexLocal(locals, pid)
if x := l.private; x != nil {
l.private = nil
return x
}
for i := 0; i int(size); i++ {
l := indexLocal(locals, (pid+i)%int(size))
if x, _ := l.shared.popTail(); x != nil {
return x
}
}
// 清空 victim cache�����。下次就不用再從這里找了
atomic.StoreUintptr(p.victimSize, 0)
return nil
}
從索引為 pid+1 的 poolLocal 處開始�,嘗試調(diào)用 shared.popTail() 獲取緩存對象��。如果沒有拿到����,則從 victim 里找��,和 poolLocal 的邏輯類似�����。
最后��,實在沒找到����,就把 victimSize 置 0�,防止后來的“人”再到 victim 里找。
在 Get 函數(shù)的最后����,經(jīng)過這一番操作還是沒找到緩存的對象,就調(diào)用 New 函數(shù)創(chuàng)建一個新的對象。
popTail
最后,還剩一個 popTail 函數(shù):
func (c *poolChain) popTail() (interface{}, bool) {
d := loadPoolChainElt(c.tail)
if d == nil {
return nil, false
}
for {
d2 := loadPoolChainElt(d.next)
if val, ok := d.popTail(); ok {
return val, ok
}
if d2 == nil {
// 雙向鏈表只有一個尾節(jié)點�,現(xiàn)在為空
return nil, false
}
// 雙向鏈表的尾節(jié)點里的雙端隊列被“掏空”�����,所以繼續(xù)看下一個節(jié)點���。
// 并且由于尾節(jié)點已經(jīng)被“掏空”,所以要甩掉它����。這樣,下次 popHead 就不會再看它有沒有緩存對象了���。
if atomic.CompareAndSwapPointer((*unsafe.Pointer)(unsafe.Pointer(c.tail)), unsafe.Pointer(d), unsafe.Pointer(d2)) {
// 甩掉尾節(jié)點
storePoolChainElt(d2.prev, nil)
}
d = d2
}
}
在 for 循環(huán)的一開始����,就把 d.next 加載到了 d2�。因為 d 可能會短暫為空,但如果 d2 在 pop 或者 pop fails 之前就不為空的話�����,說明 d 就會永久為空了��。在這種情況下���,可以安全地將 d 這個結(jié)點“甩掉”��。
最后����,將 c.tail 更新為 d2,可以防止下次 popTail 的時候查看一個空的 dequeue��;而將 d2.prev 設(shè)置為 nil�����,可以防止下次 popHead 時查看一個空的 dequeue�。
我們再看一下核心的 poolDequeue.popTail:
// src/sync/poolqueue.go:147
func (d *poolDequeue) popTail() (interface{}, bool) {
var slot *eface
for {
ptrs := atomic.LoadUint64(d.headTail)
head, tail := d.unpack(ptrs)
// 判斷隊列是否空
if tail == head {
// Queue is empty.
return nil, false
}
// 先搞定 head 和 tail 指針位置。如果搞定�,那么這個 slot 就歸屬我們了
ptrs2 := d.pack(head, tail+1)
if atomic.CompareAndSwapUint64(d.headTail, ptrs, ptrs2) {
// Success.
slot = d.vals[tailuint32(len(d.vals)-1)]
break
}
}
// We now own slot.
val := *(*interface{})(unsafe.Pointer(slot))
if val == dequeueNil(nil) {
val = nil
}
slot.val = nil
atomic.StorePointer(slot.typ, nil)
// At this point pushHead owns the slot.
return val, true
}
popTail 從隊列尾部移除一個元素,如果隊列為空�,返回 false。此函數(shù)可能同時被多個消費者調(diào)用��。
函數(shù)的核心是一個無限循環(huán)�����,又是一個無鎖編程�����。先解出 head,tail 指針值���,如果兩者相等�����,說明隊列為空。
因為要從尾部移除一個元素��,所以 tail 指針前進 1��,然后使用原子操作設(shè)置 headTail��。
最后����,將要移除的 slot 的 val 和 typ “歸零”:
slot.val = nil
atomic.StorePointer(slot.typ, nil)
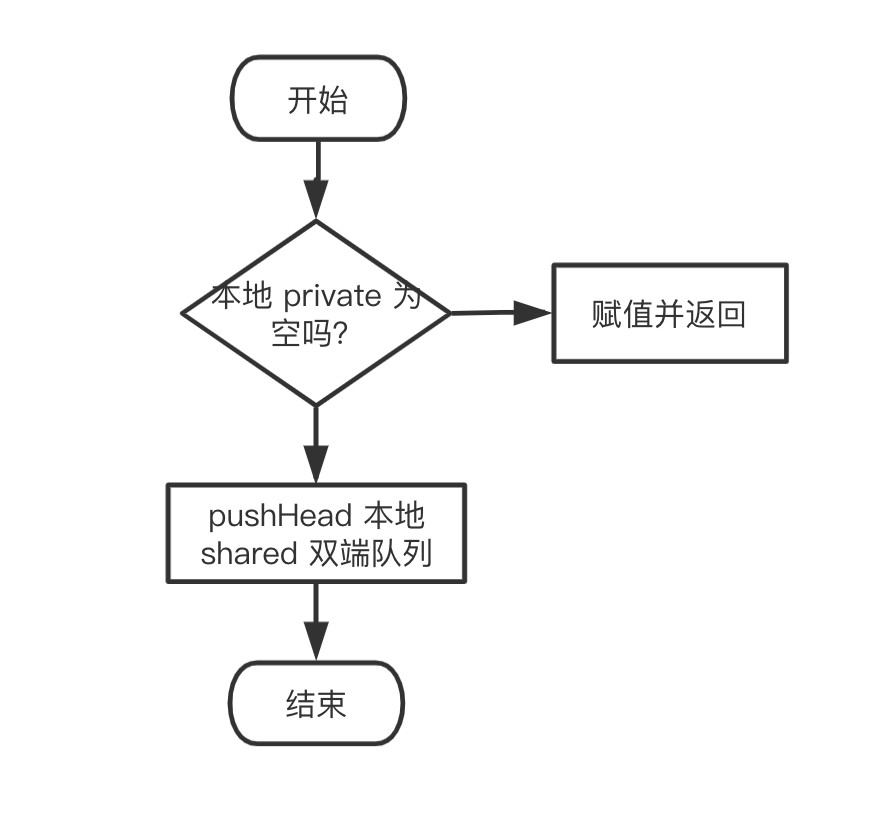
Put
// src/sync/pool.go
// Put 將對象添加到 Pool
func (p *Pool) Put(x interface{}) {
if x == nil {
return
}
// ……
l, _ := p.pin()
if l.private == nil {
l.private = x
x = nil
}
if x != nil {
l.shared.pushHead(x)
}
runtime_procUnpin()
//……
}
同樣刪掉了 race 相關(guān)的函數(shù),看起來清爽多了�。整個 Put 的邏輯也很清晰:
- 先綁定 g 和 P,然后嘗試將 x 賦值給 private 字段��。
- 如果失敗���,就調(diào)用
pushHead 方法嘗試將其放入 shared 字段所維護的雙端隊列中�����。
同樣用流程圖來展示整個過程:
pushHead
我們來看 pushHead 的源碼�����,比較清晰:
// src/sync/poolqueue.go
func (c *poolChain) pushHead(val interface{}) {
d := c.head
if d == nil {
// poolDequeue 初始長度為8
const initSize = 8 // Must be a power of 2
d = new(poolChainElt)
d.vals = make([]eface, initSize)
c.head = d
storePoolChainElt(c.tail, d)
}
if d.pushHead(val) {
return
}
// 前一個 poolDequeue 長度的 2 倍
newSize := len(d.vals) * 2
if newSize >= dequeueLimit {
// Can't make it any bigger.
newSize = dequeueLimit
}
// 首尾相連�,構(gòu)成鏈表
d2 := poolChainElt{prev: d}
d2.vals = make([]eface, newSize)
c.head = d2
storePoolChainElt(d.next, d2)
d2.pushHead(val)
}
如果 c.head 為空,就要創(chuàng)建一個 poolChainElt����,作為首結(jié)點,當然也是尾節(jié)點���。它管理的雙端隊列的長度��,初始為 8��,放滿之后�����,再創(chuàng)建一個 poolChainElt 節(jié)點時���,雙端隊列的長度就要翻倍。當然,有一個最大長度限制(2^30):
const dequeueBits = 32
const dequeueLimit = (1 dequeueBits) / 4
調(diào)用 poolDequeue.pushHead 嘗試將對象放到 poolDeque 里去:
// src/sync/poolqueue.go
// 將 val 添加到雙端隊列頭部��。如果隊列已滿����,則返回 false。此函數(shù)只能被一個生產(chǎn)者調(diào)用
func (d *poolDequeue) pushHead(val interface{}) bool {
ptrs := atomic.LoadUint64(d.headTail)
head, tail := d.unpack(ptrs)
if (tail+uint32(len(d.vals)))(1dequeueBits-1) == head {
// 隊列滿了
return false
}
slot := d.vals[headuint32(len(d.vals)-1)]
// 檢測這個 slot 是否被 popTail 釋放
typ := atomic.LoadPointer(slot.typ)
if typ != nil {
// 另一個 groutine 正在 popTail 這個 slot�,說明隊列仍然是滿的
return false
}
// The head slot is free, so we own it.
if val == nil {
val = dequeueNil(nil)
}
// slot占位,將val存入vals中
*(*interface{})(unsafe.Pointer(slot)) = val
// head 增加 1
atomic.AddUint64(d.headTail, 1dequeueBits)
return true
}
首先判斷隊列是否已滿:
if (tail+uint32(len(d.vals)))(1dequeueBits-1) == head {
// Queue is full.
return false
}
也就是將尾部指針加上 d.vals 的長度����,再取低 31 位��,看它是否和 head 相等�。我們知道,d.vals 的長度實際上是固定的���,因此如果隊列已滿��,那么 if 語句的兩邊就是相等的��。如果隊列滿了����,直接返回 false。
否則�,隊列沒滿,通過 head 指針找到即將填充的 slot 位置:取 head 指針的低 31 位��。
// Check if the head slot has been released by popTail.
typ := atomic.LoadPointer(slot.typ)
if typ != nil {
// Another goroutine is still cleaning up the tail, so
// the queue is actually still full.
// popTail 是先設(shè)置 val���,再將 typ 設(shè)置為 nil�����。設(shè)置完 typ 之后��,popHead 才可以操作這個 slot
return false
}
上面這一段用來判斷是否和 popTail 有沖突發(fā)生��,如果有�,則直接返回 false��。
最后���,將 val 賦值到 slot�����,并將 head 指針值加 1���。
// slot占位�,將val存入vals中
*(*interface{})(unsafe.Pointer(slot)) = val
這里的實現(xiàn)比較巧妙����,slot 是 eface 類型,將 slot 轉(zhuǎn)為 interface{} 類型���,這樣 val 能以 interface{} 賦值給 slot 讓 slot.typ 和 slot.val 指向其內(nèi)存塊��,于是 slot.typ 和 slot.val 均不為空�����。
pack/unpack
最后我們再來看一下 pack 和 unpack 函數(shù),它們實際上是一組綁定��、解綁 head 和 tail 指針的兩個函數(shù)����。
// src/sync/poolqueue.go
const dequeueBits = 32
func (d *poolDequeue) pack(head, tail uint32) uint64 {
const mask = 1dequeueBits - 1
return (uint64(head) dequeueBits) |
uint64(tailmask)
}
mask 的低 31 位為全 1,其他位為 0�����,它和 tail 相與,就是只看 tail 的低 31 位���。而 head 向左移 32 位之后��,低 32 位為全 0��。最后把兩部分“或”起來�,head 和 tail 就“綁定”在一起了��。
相應的解綁函數(shù):
func (d *poolDequeue) unpack(ptrs uint64) (head, tail uint32) {
const mask = 1dequeueBits - 1
head = uint32((ptrs >> dequeueBits) mask)
tail = uint32(ptrs mask)
return
}
取出 head 指針的方法就是將 ptrs 右移 32 位�����,再與 mask 相與�,同樣只看 head 的低 31 位。而 tail 實際上更簡單����,直接將 ptrs 與 mask 相與就可以了。
GC
對于 Pool 而言�,并不能無限擴展,否則對象占用內(nèi)存太多了��,會引起內(nèi)存溢出�����。
幾乎所有的池技術(shù)中,都會在某個時刻清空或清除部分緩存對象��,那么在 Go 中何時清理未使用的對象呢����?
答案是 GC 發(fā)生時。
在 pool.go 文件的 init 函數(shù)里��,注冊了 GC 發(fā)生時�,如何清理 Pool 的函數(shù):
// src/sync/pool.go
func init() {
runtime_registerPoolCleanup(poolCleanup)
}
編譯器在背后做了一些動作:
// src/runtime/mgc.go
// Hooks for other packages
var poolcleanup func()
// 利用編譯器標志將 sync 包中的清理注冊到運行時
//go:linkname sync_runtime_registerPoolCleanup sync.runtime_registerPoolCleanup
func sync_runtime_registerPoolCleanup(f func()) {
poolcleanup = f
}
具體來看下:
func poolCleanup() {
for _, p := range oldPools {
p.victim = nil
p.victimSize = 0
}
// Move primary cache to victim cache.
for _, p := range allPools {
p.victim = p.local
p.victimSize = p.localSize
p.local = nil
p.localSize = 0
}
oldPools, allPools = allPools, nil
}
poolCleanup 會在 STW 階段被調(diào)用。整體看起來�,比較簡潔。主要是將 local 和 victim 作交換����,這樣也就不致于讓 GC 把所有的 Pool 都清空了,有 victim 在“兜底”�����。
如果 sync.Pool 的獲取��、釋放速度穩(wěn)定����,那么就不會有新的池對象進行分配。如果獲取的速度下降了����,那么對象可能會在兩個 GC 周期內(nèi)被釋放,而不是以前的一個 GC 周期����。
鳥窩的【Go 1.13中 sync.Pool 是如何優(yōu)化的?】講了 1.13 中的優(yōu)化。
參考資料【理解 Go 1.13 中 sync.Pool 的設(shè)計與實現(xiàn)】 手動模擬了一下調(diào)用 poolCleanup 函數(shù)前后 oldPools�,allPools,p.vitcim 的變化過程��,很精彩:
初始狀態(tài)下����,oldPools 和 allPools 均為 nil。
第 1 次調(diào)用 Get���,由于 p.local 為 nil���,將會在 pinSlow 中創(chuàng)建 p.local,然后將 p 放入 allPools��,此時 allPools 長度為 1,oldPools 為 nil��。對象使用完畢���,第 1 次調(diào)用 Put 放回對象���。第 1 次GC STW 階段,allPools 中所有 p.local 將值賦值給 victim 并置為 nil����。allPools 賦值給 oldPools,最后 allPools 為 nil���,oldPools 長度為 1�����。第 2 次調(diào)用 Get�����,由于 p.local 為 nil��,此時會從 p.victim 里面嘗試取對象���。對象使用完畢,第 2 次調(diào)用 Put 放回對象��,但由于 p.local 為 nil����,重新創(chuàng)建 p.local,并將對象放回�,此時 allPools 長度為 1,oldPools 長度為 1���。第 2 次 GC STW 階段���,oldPools 中所有 p.victim 置 nil,前一次的 cache 在本次 GC 時被回收����,allPools 所有 p.local 將值賦值給 victim 并置為nil,最后 allPools 為 nil���,oldPools 長度為 1���。
我根據(jù)這個流程畫了一張圖�����,可以理解地更清晰一些:
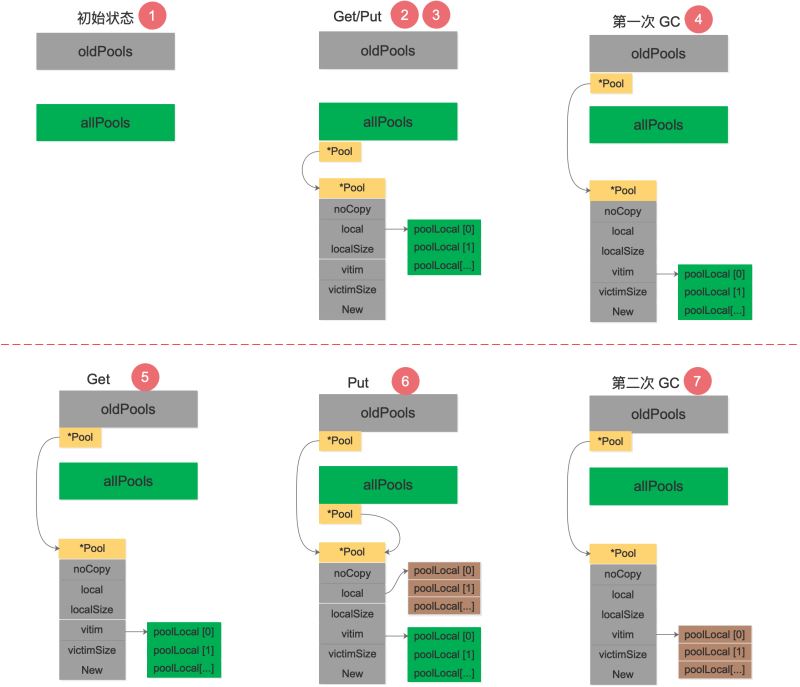
需要指出的是���,allPools 和 oldPools 都是切片,切片的元素是指向 Pool 的指針�,Get/Put 操作不需要通過它們。在第 6 步�����,如果還有其他 Pool 執(zhí)行了 Put 操作���,allPools 這時就會有多個元素�����。
在 Go 1.13 之前的實現(xiàn)中��,poolCleanup 比較“簡單粗暴”:
func poolCleanup() {
for i, p := range allPools {
allPools[i] = nil
for i := 0; i int(p.localSize); i++ {
l := indexLocal(p.local, i)
l.private = nil
for j := range l.shared {
l.shared[j] = nil
}
l.shared = nil
}
p.local = nil
p.localSize = 0
}
allPools = []*Pool{}
}
直接清空了所有 Pool 的 p.local 和 poolLocal.shared���。
通過兩者的對比發(fā)現(xiàn)���,新版的實現(xiàn)相比 Go 1.13 之前,GC 的粒度拉大了�,由于實際回收的時間線拉長����,單位時間內(nèi) GC 的開銷減小。
由此基本明白 p.victim 的作用�����。它的定位是次級緩存���,GC 時將對象放入其中����,下一次 GC 來臨之前如果有 Get 調(diào)用則會從 p.victim 中取�����,直到再一次 GC 來臨時回收����。
同時由于從 p.victim 中取出對象使用完畢之后并未放回 p.victim 中,在一定程度也減小了下一次 GC 的開銷。原來 1 次 GC 的開銷被拉長到 2 次且會有一定程度的開銷減小��,這就是 p.victim 引入的意圖���。
【理解 Go 1.13 中 sync.Pool 的設(shè)計與實現(xiàn)】 這篇文章最后還總結(jié)了 sync.Pool 的設(shè)計理念����,包括:無鎖��、操作對象隔離���、原子操作代替鎖���、行為隔離——鏈表、Victim Cache 降低 GC 開銷���。寫得非常不錯��,推薦閱讀��。
另外�����,關(guān)于 sync.Pool 中鎖競爭優(yōu)化的文章����,推薦閱讀芮大神的【優(yōu)化鎖競爭】。
總結(jié)
本文先是介紹了 Pool 是什么��,有什么作用�����,接著給出了 Pool 的用法以及在標準庫��、一些第三方庫中的用法�����,還介紹了 pool_test 中的一些測試用例�����。最后���,詳細解讀了 sync.Pool 的源碼。
本文的結(jié)尾部分���,再來詳細地總結(jié)一下關(guān)于 sync.Pool 的要點:
- 關(guān)鍵思想是對象的復用���,避免重復創(chuàng)建�����、銷毀���。將暫時不用的對象緩存起來,待下次需要的時候直接使用�,不用再次經(jīng)過內(nèi)存分配,復用對象的內(nèi)存���,減輕 GC 的壓力���。
sync.Pool 是協(xié)程安全的,使用起來非常方便��。設(shè)置好 New 函數(shù)后���,調(diào)用 Get 獲取�����,調(diào)用 Put 歸還對象�。- Go 語言內(nèi)置的 fmt 包����,encoding/json 包都可以看到 sync.Pool 的身影��;
gin,Echo 等框架也都使用了 sync.Pool�����。
- 不要對 Get 得到的對象有任何假設(shè)����,更好的做法是歸還對象時�����,將對象“清空”����。
- Pool 里對象的生命周期受 GC 影響���,不適合于做連接池,因為連接池需要自己管理對象的生命周期����。
- Pool 不可以指定⼤⼩���,⼤⼩只受制于 GC 臨界值��。
procPin 將 G 和 P 綁定���,防止 G 被搶占。在綁定期間��,GC 無法清理緩存的對象���。- 在加入
victim 機制前����,sync.Pool 里對象的最⼤緩存時間是一個 GC 周期���,當 GC 開始時����,沒有被引⽤的對象都會被清理掉;加入 victim 機制后����,最大緩存時間為兩個 GC 周期��。
- Victim Cache 本來是計算機架構(gòu)里面的一個概念�,是 CPU 硬件處理緩存的一種技術(shù)���,
sync.Pool 引入的意圖在于降低 GC 壓力的同時提高命中率��。
sync.Pool 的最底層使用切片加鏈表來實現(xiàn)雙端隊列��,并將緩存的對象存儲在切片中����。
參考資料
【歐神 源碼分析】https://changkun.us/archives/2018/09/256/
【Go 夜讀】https://reading.hidevops.io/reading/20180817/2018-08-17-sync-pool-reading.pdf
【夜讀第 14 期視頻】https://www.youtube.com/watch?v=jaepwn2PWPklist=PLe5svQwVF1L5bNxB0smO8gNfAZQYWdIpI
【源碼分析��,偽共享】https://juejin.im/post/5d4087276fb9a06adb7fbe4a
【golang的對象池sync.pool源碼解讀】https://zhuanlan.zhihu.com/p/99710992
【理解 Go 1.13 中 sync.Pool 的設(shè)計與實現(xiàn)】https://zhuanlan.zhihu.com/p/110140126
【優(yōu)缺點�,圖】http://cbsheng.github.io/posts/golang標準庫sync.pool原理及源碼簡析/
【xiaorui 優(yōu)化鎖競爭】http://xiaorui.cc/archives/5878
【性能優(yōu)化之路�����,自定義多種規(guī)格的緩存】https://blog.cyeam.com/golang/2017/02/08/go-optimize-slice-pool
【sync.Pool 有什么缺點】https://mp.weixin.qq.com/s?__biz=MzA4ODg0NDkzOA==mid=2247487149idx=1sn=f38f2d72fd7112e19e97d5a2cd304430source=41
【1.12 和 1.13 的演變】https://github.com/watermelo/dailyTrans/blob/master/golang/sync_pool_understand.md
【董澤潤 演進】https://www.jianshu.com/p/2e08332481c5
【noCopy】https://github.com/golang/go/issues/8005
【董澤潤 cpu cache】https://www.jianshu.com/p/dc4b5562aad2
【gomemcache 例子】https://docs.kilvn.com/The-Golang-Standard-Library-by-Example/chapter16/16.01.html
【鳥窩 1.13 優(yōu)化】https://colobu.com/2019/10/08/how-is-sync-Pool-improved-in-Go-1-13/
【A journey with go】https://medium.com/a-journey-with-go/go-understand-the-design-of-sync-pool-2dde3024e277
【封裝了一個計數(shù)組件】https://www.akshaydeo.com/blog/2017/12/23/How-did-I-improve-latency-by-700-percent-using-syncPool/
【偽共享】http://ifeve.com/falsesharing/
到此這篇關(guān)于深度解密 Go 語言之 sync.Pool的文章就介紹到這了,更多相關(guān)go sync.pool內(nèi)容請搜索腳本之家以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持腳本之家����!
您可能感興趣的文章:- go語言中int和byte轉(zhuǎn)換方式
- Go語言中的字符串處理方法示例詳解
- Go語言的http/2服務器功能及客戶端使用

