目錄
- 一、查詢優(yōu)化
- 1�����,mysql的調優(yōu)大綱
- 2��,小表驅動大表
- 3��,in和exists
- 4����,orderby創(chuàng)建表
- 5,groupby優(yōu)化
- 二��、慢查詢日志
- 1�,慢查詢日志是什么?
- 2,慢查詢日志的開啟
- 3����,日志分析命令mysqldumpslow
- 三���、批量寫數據腳本
- 1,建表
- 4��,創(chuàng)建存儲過程
- 5�����,調用存儲過程生成數據
- 四��、show profiles
- 五�����、全局查詢日志
- 總結
一�����、查詢優(yōu)化
1�����,mysql的調優(yōu)大綱
- 慢查詢的開啟并捕獲
- explain+慢SQL分析
- show profile查詢SQL在Mysql服務器里面的執(zhí)行細節(jié)和生命周期情況
- SQL數據庫服務器的參數調優(yōu)
2,小表驅動大表
mysql的join實現(xiàn)原理是�,以驅動表的數據為基礎,“嵌套循環(huán)”去被驅動表匹配記錄���。驅動表的索引會失效�,而被驅動表的索引有效�。
#假設 a表10000數據��,b表20數據
select * from a join b on a.bid =b.id
a表驅動b表為:
for 20條數據
匹配10000數據(根據on a.bid=b.id的連接條件����,進行B+樹查找)
查找次數為:20+ log10000
b表驅動a表為
for 10000條數據
匹配20條數據(根據on a.bid=b.id的連接條件,進行B+樹查找)查找次數為:10000+ log20
3����,in和exists
exists的使用
- EXISTS 語法:EXISTS(subquery) 只返回TRUE或FALSE,因此子查詢中的SELECT *也可以是SELECT 1或其他�,官方說法是實際執(zhí)行時會忽略SELECT清單,因此沒有區(qū)別
- SELECT ... FROM table WHERE EXISTS(subquery)
- 該語法可以理解為:將查詢的數據�����,放到子查詢中做條件驗證�����,根據驗證結果(TRUE或FALSE)來決定主查詢的數據結果是否得以保留。
- EXISTS子查詢的實際執(zhí)行過程可能經過了優(yōu)化而不是我們理解上的逐條對比�,如果擔憂效率問題,可進行實際檢驗以確定是否有效率問題�����。
- EXISTS子查詢往往也可以用條件表達式��、其他子查詢或者JOIN來替代����,何種最優(yōu)需要具體問題具體分析
#采用in則是,內表B驅動外表A
select * from A where id in (select id from B)
#采用exists則是���,外表A驅動內表B
select * from A where exists(select 1 from B where B.id = A.id)
結論:
永遠記住小表驅動大表
當 B 表數據集小于 A 表數據集時�����,使用 in
當 A 表數據集小于 B 表數據集時�����,使用 exist
4����,orderby創(chuàng)建表
create table tblA(
#id int primary key not null auto_increment,
age int,
birth timestamp not null
);
insert into tblA(age, birth) values(22, now());
insert into tblA(age, birth) values(23, now());
insert into tblA(age, birth) values(24, now());
#創(chuàng)建復合索引
create index idx_A_ageBirth on tblA(age, birth);

orderby命中索引的情況

orderby未命中索引的情況

- MySQL支持兩種排序方式:Using index和Using filesort。filesort效率較低��,而要使用index方式排序需滿足兩種使用條件盡可能在索引列上完成排序操作��,遵照索引的最佳左前綴
- order by語句自身使用索引的最左前列
- 使用where子句與order by子句條件列組合滿足最左前列
- 如果order by不在索引列上���,會使用filesort算法:雙路排序和單路排序
- MySQL4.1之前是使用雙路排序��,字面意思是兩次掃描磁盤,最終得到數據�����。讀取行指針和order by列�,對他們進行排序,然后掃描已經排序好的列表�����,按照列表中的值重新從列表中讀取對應的數據傳輸
- 從磁盤讀取查詢需要的所有列��,按照order by列在buffer對它們進行排序�,然后掃描排序后的列表進行輸出��,它的效率更快一些�����,避免了第二次讀取數據����,并且把隨機IO變成順序IO���,但是它會使用更多的空間�����,因為它把每一行都保存在內存中了����。
select * from user where name = "zs" order by age
#雙路排序
1)從 name 找到第一個滿足 name = 'zs' 的主鍵id
2)根據主鍵 id 取出整行��,把排序字段 age 和主鍵 id 這兩個字段放到 sort buffer(排序緩存) 中
3)從name 取下一個滿足 name = 'zs' 記錄的主鍵 id
4)重復 2���、3 直到不滿足 name = 'zs'
5)對 sort_buffer 中的字段 age 和主鍵 id 按照字段 age進行排序
6)遍歷排序好的 id 和字段 age ��,按照 id 的值回到原表中取出 所有字段的值返回給客戶端
#單路排序
1)從name找到第一個滿足 name ='zs' 條件的主鍵 id
2)根據主鍵 id 取出整行�����,取出所有字段的值����,存入 sort_buffer(排序緩存)中
3)從索引name找到下一個滿足 name = 'zs' 條件的主鍵 id
4)重復步驟 2、3 直到不滿足 name = 'zs'
5)對 sort_buffer 中的數據按照字段 age 進行排序���,返回結果給客戶端
單路排序的問題及優(yōu)化
問題:
由于單路是改進的算法��,總體而言好過雙路
在sort_buffer中�,方法B比方法A要多占用很多空間�,因為方法B是把所有字段都取出,所以有可能取出的數據的總大小超出了sort_buffer的容量��,導致每次只能取sort_buffer容量大小的數據�,進行排序(創(chuàng)建tmp文件����,多路合并),排完再取取sort_buffer容量大小�,再排…… 從而會導致多次I/O。
優(yōu)化策略:
增大sort_buffer_size參數的設置
增大max_length_for_sort_data參數的設置
注意事項:
Order by時select *是一個大忌��,只Query需要的字段。因為字段越多在內存中存儲的數據也就也多��,這樣就導致每次I/O能加載的數據列越少����。
5,groupby優(yōu)化
1)group by實質是先排序后進行分組�,遵照索引的最佳左前綴
2)當無法使用索引列,增大max_length_for_sort_data參數的設置+增大sort_buffer_size參數的設置
3)where高于having����,能寫在where限定的條件就不要去having限定了
4)其余的規(guī)則均和 order by 一致
二、慢查詢日志
1��,慢查詢日志是什么?
- MySQL的慢查詢日志是MySQL提供的一種日志記錄����,它用來記錄在MySQL中響應時間超過閥值的語句,具體指運行時間超過long_query_time值的SQL���,則會被記錄到慢查詢日志中���。
- long_query_time的默認值為10,意思是運行10秒以上的SQL語句會被記錄下來
- 由他來查看哪些SQL超出了我們的最大忍耐時間值,比如一條sql執(zhí)行超過5秒鐘�,我們就算慢SQL,希望能收集超過5秒的sql���,結合之前explain進行全面分析��。
2�,慢查詢日志的開啟
默認情況下��,MySQL的慢查詢日志是沒有開啟的��。如果不是調優(yōu)需要的話����,一般不建議啟動該參數,因為開啟慢查詢日志會影響到性能���,慢查詢日志支持將日志記錄寫入文件��。
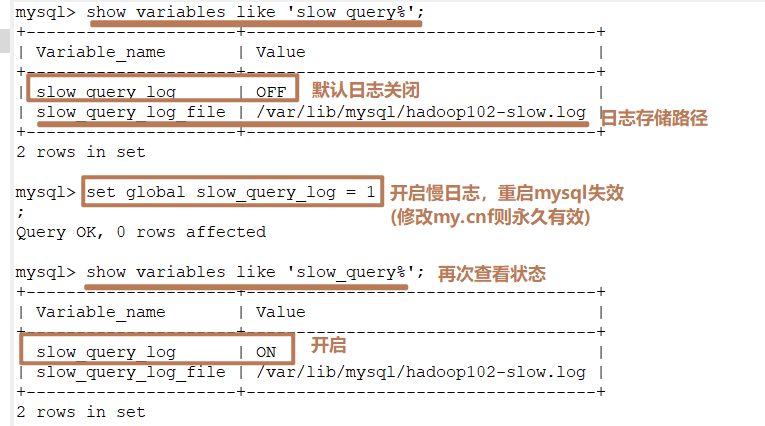
a)開啟慢查詢日志
#查看是否開啟慢日志
show variables like 'slow_query_log%';
#開啟慢查詢日志,想要永久有效在my.cnf中設置
set global slow_query_log = 1 ;
b)設置慢查詢日志的閾值
#查看慢查詢日志的閾值時間 默認為10s
show variables like 'long_query_time%';
#設置為3s 重啟失效�����,想要永久有效在my.cnf中設置
set global long_query_time = 3
#再次查看,需要切換窗口查看
show variables like 'long_query_time%';

c)持久化慢查詢日志和時間閾值
[mysqld]
#持久化慢查詢日志
slow_query_log=1��;
slow_query_log_file=/var/lib/mysql/hadoop102-slow.log
long_query_time=3��;
log_output=FILE
d)慢查詢案例
#在linux系統(tǒng)中��,查看慢查詢日志
cat /var/lib/mysql/hadoop102-slow.log
e)查看當前系統(tǒng)中存在的慢查詢日志條數
show global status like '%Slow_queries%';
3��,日志分析命令mysqldumpslow
a)參數解釋
-s:是表示按何種方式排序
c:訪問次數
l:鎖定時間
r:返回記錄
t:查詢時間
al:平均鎖定時間
ar:平均返回記錄數
at:平均查詢時間
-t:即為返回前面多少條的數據
-g:后邊搭配一個正則匹配模式,大小寫不敏感的
b)常用方法
#得到返回記錄集最多的10個SQL
mysqldumpslow -s r -t 10 /var/lib/mysql/hadoop102-slow.log
#得到訪問次數最多的10個SQL
mysqldumpslow -s c -t 10 /var/lib/mysql/hadoop102-slow.log
#得到按照時間排序的前10條里面含有左連接的查詢語句
mysqldumpslow -s t -t 10 -g "left join" /var/lib/mysql/hadoop102-slow.log
#這些命令時結合 | 和more使用
mysqldumpslow -s r -t 10 /var/lib/mysql/hadoop102-slow.log | more
三、批量寫數據腳本
1���,建表
CREATE TABLE dept
(
deptno int unsigned primary key auto_increment,
dname varchar(20) not null default '',
loc varchar(8) not null default ''
)ENGINE=INNODB DEFAULT CHARSET=utf8;
CREATE TABLE emp
(
id int unsigned primary key auto_increment,
empno mediumint unsigned not null default 0,
ename varchar(20) not null default '',
job varchar(9) not null default '',
mgr mediumint unsigned not null default 0,
hiredate date not null,
sal decimal(7,2) not null,
comm decimal(7,2) not null,
deptno mediumint unsigned not null default 0
)ENGINE=INNODB DEFAULT CHARSET=utf8;
2���,設置是否可以信任存儲函數創(chuàng)建者
#查看binlog狀態(tài)
show variables like 'log_bin%';
#添加可以信任存儲函數創(chuàng)建者
set global log_bin_trust_function_creators = 1;

3����,創(chuàng)建函數
隨機產生字符串的函數
# 定義兩個 $$ 表示結束 (替換原先的;)
delimiter $$
create function rand_string(n int) returns varchar(255)
begin
declare chars_str varchar(100) default 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ';
declare return_str varchar(255) default '';
declare i int default 0;
while i n do
set return_str = concat(return_str,substring(chars_str,floor(1+rand()*52),1));
set i=i+1;
end while;
return return_str;
end $$
隨機產生部門編號的函數
delimiter $$
create function rand_num() returns int(5)
begin
declare i int default 0;
set i=floor(100+rand()*10);
return i;
end $$
4,創(chuàng)建存儲過程
創(chuàng)建往emp表中插入數據的存儲過程
delimiter $$
create procedure insert_emp(in start int(10),in max_num int(10))
begin
declare i int default 0;
set autocommit = 0;
repeat
set i = i+1;
insert into emp(empno,ename,job,mgr,hiredate,sal,comm,deptno) values((start+i),rand_string(6),'salesman',0001,curdate(),2000,400,rand_num());
until i=max_num
end repeat;
commit;
end $$
創(chuàng)建往dept表中插入數據的存儲過程
delimiter $$
create procedure insert_dept(in start int(10),in max_num int(10))
begin
declare i int default 0;
set autocommit = 0;
repeat
set i = i+1;
insert into dept(deptno,dname,loc) values((start+i),rand_string(10),rand_string(8));
until i=max_num
end repeat;
commit;
end $$
5�,調用存儲過程生成數據
#向 部門表插入10條數據
DELIMITER ;
CALL insert_dept(100, 10);
#向 員工表插入50w條數據
CALL insert_emp(100001, 500000);
四�、show profiles
1�,介紹
- show profile是mysql提供可以用來分析當前會話中語句執(zhí)行的資源消耗情況���。可以用于SQL的調優(yōu)測量�����。
- 默認情況下,參數處于關閉狀態(tài)�����,并保存最近15次的運行結果
2,開啟
#查看 Show Profile 是否開啟
show variables like ‘profiling%';
#開啟 Show Profile
set profiling=on;
3,使用show profiles
創(chuàng)建測試數據
select * from emp group by id%10 limit 150000;
select * from emp group by id%10 limit 150000;
select * from emp group by id%10 order by 5;
select * from emp
select * from dept
select * from emp left join dept on emp.deptno = dept.deptno
執(zhí)行show profiles

執(zhí)行 show profile cpu, block io for query Query_ID;
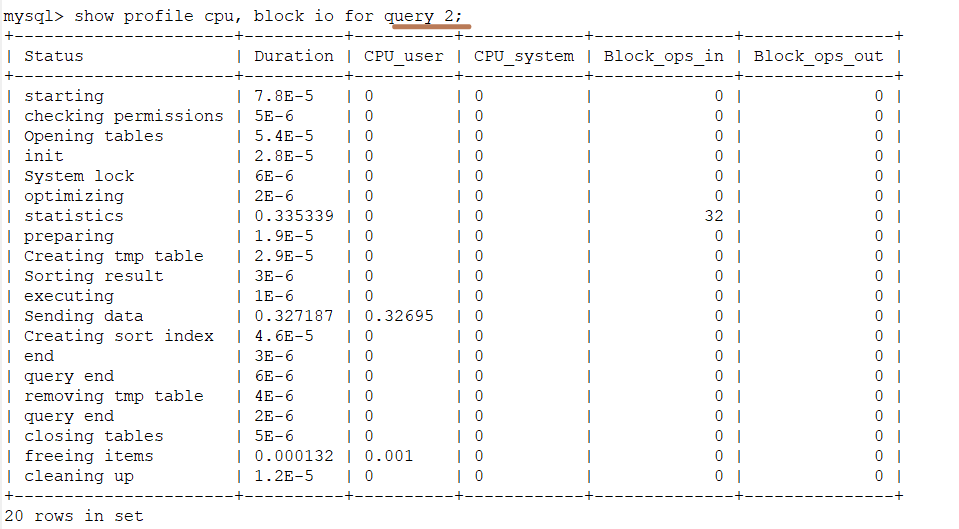
檢索參數
ALL:顯示所有的開銷信息
BLOCK IO:顯示塊IO相關開銷
CONTEXT SWITCHES:上下文切換相關開銷
CPU:顯示CPU相關開銷信息
IPC:顯示發(fā)送和接收相關開銷信息
MEMORY:顯示內存相關開銷信息
PAGE FAULTS:顯示頁面錯誤相關開銷信息
SOURCE:顯示和Source_function,Source_file����,Source_line相關的開銷信息
SWAPS:顯示交換次數相關開銷的信息
返回結果
converting HEAP to MyISAM:查詢結果太大�����,內存都不夠用了往磁盤上搬了。
Creating tmp table:創(chuàng)建臨時表�����,mysql 先將拷貝數據到臨時表,然后用完再將臨時表刪除
Copying to tmp table on disk:把內存中臨時表復制到磁盤�,危險?��。�。?br />
locked:鎖表
五����、全局查詢日志
切莫在生產環(huán)境配置啟用
在my.cnf中配置
# 開啟
general_log=1
# 記錄日志文件的路徑
general_log_file=/path/logfile
# 輸出格式
log_output=FILE
編碼啟用
set global general_log=1;
set global log_output='TABLE';
配置完成之后,將會記錄到mysql庫里的general_log表
select * from mysql.general_log;
總結
到此這篇關于MySQL查詢截取的文章就介紹到這了,更多相關MySQL查詢截取內容請搜索腳本之家以前的文章或繼續(xù)瀏覽下面的相關文章希望大家以后多多支持腳本之家�!
您可能感興趣的文章:- Mysql字符串截取函數SUBSTRING的用法說明
- MySql用DATE_FORMAT截取DateTime字段的日期值
- MySQL截取和拆分字符串函數用法示例
- Mysql字符串截取及獲取指定字符串中的數據
- mysql截取的字符串函數substring_index的用法
- mysql 截取指定的兩個字符串之間的內容
- MySQL 截取字符串函數的sql語句
- mysql截取函數常用方法使用說明
- MySQL 字符串截取相關函數小結
- mysql中循環(huán)截取用戶信息并插入到目標表對應的字段中

