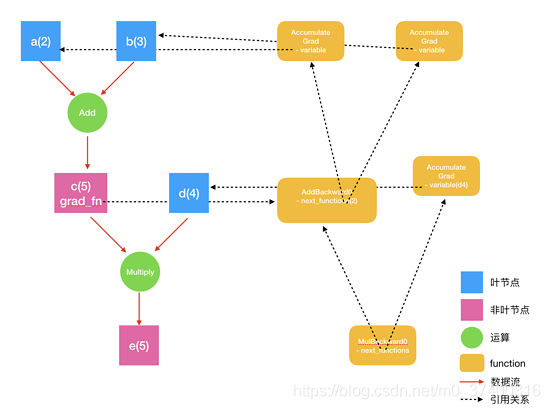
在PyTorch實現(xiàn)中��,autograd會隨著用戶的操作,記錄生成當前variable的所有操作��,并由此建立一個有向無環(huán)圖。用戶每進行一個操作����,相應的計算圖就會發(fā)生改變���。
更底層的實現(xiàn)中,圖中記錄了操作Function�����,每一個變量在圖中的位置可通過其grad_fn屬性在圖中的位置推測得到���。在反向傳播過程中�����,autograd沿著這個圖從當前變量(根節(jié)點\textbf{z}z)溯源,可以利用鏈式求導法則計算所有葉子節(jié)點的梯度����。
每一個前向傳播操作的函數(shù)都有與之對應的反向傳播函數(shù)用來計算輸入的各個variable的梯度����,這些函數(shù)的函數(shù)名通常以Backward結尾����。
下面結合代碼學習autograd的實現(xiàn)細節(jié)。
在PyTorch中計算圖的特點可總結如下:
autograd根據(jù)用戶對variable的操作構建其計算圖����。對變量的操作抽象為Function
對于那些不是任何函數(shù)(Function)的輸出���,由用戶創(chuàng)建的節(jié)點稱為葉子節(jié)點�����,葉子節(jié)點的grad_fn為None。葉子節(jié)點中需要求導的variable��,具有AccumulateGrad標識,因其梯度是累加的
variable默認是不需要求導的��,即requires_grad屬性默認為False�,如果某一個節(jié)點requires_grad被設置為True,那么所有依賴它的節(jié)點requires_grad都為True
variable的volatile屬性默認為False����,如果某一個variable的volatile屬性被設為True,那么所有依賴它的節(jié)點volatile屬性都為True�。volatile屬性為True的節(jié)點不會求導��,volatile的優(yōu)先級比requires_grad高。
多次反向傳播時,梯度是累加的。反向傳播的中間緩存會被清空���,為進行多次反向傳播需指定retain_graph=True來保存這些緩存
非葉子節(jié)點的梯度計算完之后即被清空�,可以使用autograd.grad或hook技術獲取非葉子節(jié)點的值
variable的grad與data形狀一致��,應避免直接修改variable.data����,因為對data的直接操作無法利用autograd進行反向傳播
反向傳播函數(shù)backward的參數(shù)grad_variables可以看成鏈式求導的中間結果����,如果是標量����,可以省略����,默認為1
PyTorch采用動態(tài)圖設計�,可以很方便地查看中間層的輸出��,動態(tài)的設計計算圖結構
在 e.backward() 執(zhí)行求導時��,系統(tǒng)遍歷 e.grad_fn.next_functions �����,分別執(zhí)行求導���。
如果 e.grad_fn.next_functions 中有哪個是 AccumulateGrad ����,則把結果保存到 AccumulateGrad 的variable引用的變量中���。
否則���,遞歸遍歷這個function的 next_functions ����,執(zhí)行求導過程�。
最終到達所有的葉節(jié)點��,求導結束�����。同時,所有的葉節(jié)點的 grad 變量都得到了相應的更新。
他們之間的關系如下圖所示:
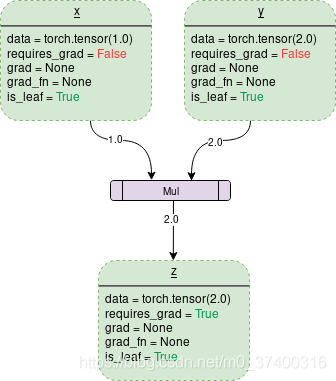
例子:
x = torch.randn(5, 5)
y = torch.randn(5, 5)
z = torch.randn((5, 5), requires_grad=True)
a = x + z
print(a.requires_grad)
可以z是一個標量��,當調用它的backward方法后會根據(jù)鏈式法則自動計算出葉子節(jié)點的梯度值����。
但是如果遇到z是一個向量或者是一個矩陣的情況���,這個時候又該怎么計算梯度呢����?這種情況我們需要定義grad_tensor來計算矩陣的梯度。在介紹為什么使用之前我們先看一下源代碼中backward的接口是如何定義的:
torch.autograd.backward(
tensors,
grad_tensors=None,
retain_graph=None,
create_graph=False,
grad_variables=None)
grad_tensors作用
x = torch.ones(2,requires_grad=True)
z = x + 2
z.backward()
>>> ...
RuntimeError: grad can be implicitly created only for scalar outputs
當我們運行上面的代碼的話會報錯�����,報錯信息為RuntimeError: grad can be implicitly created only for scalar outputs��。

x = torch.ones(2,requires_grad=True)
z = x + 2
z.sum().backward()
print(x.grad)
>>> tensor([1., 1.])
我們再仔細想想�,對z求和不就是等價于z點乘一個一樣維度的全為1的矩陣嗎?即sum(Z)=dot(Z,I),而這個I也就是我們需要傳入的grad_tensors參數(shù)�����。(點乘只是相對于一維向量而言的���,對于矩陣或更高為的張量�,可以看做是對每一個維度做點乘)
代碼如下:
x = torch.ones(2,requires_grad=True)
z = x + 2
z.backward(torch.ones_like(z)) # grad_tensors需要與輸入tensor大小一致
print(x.grad)
>>> tensor([1., 1.])
x = torch.tensor([2., 1.], requires_grad=True).view(1, 2)
y = torch.tensor([[1., 2.], [3., 4.]], requires_grad=True)
z = torch.mm(x, y)
print(f"z:{z}")
z.backward(torch.Tensor([[1., 0]]), retain_graph=True)
print(f"x.grad: {x.grad}")
print(f"y.grad: {y.grad}")
>>> z:tensor([[5., 8.]], grad_fn=MmBackward>)
x.grad: tensor([[1., 3.]])
y.grad: tensor([[2., 0.],
[1., 0.]])
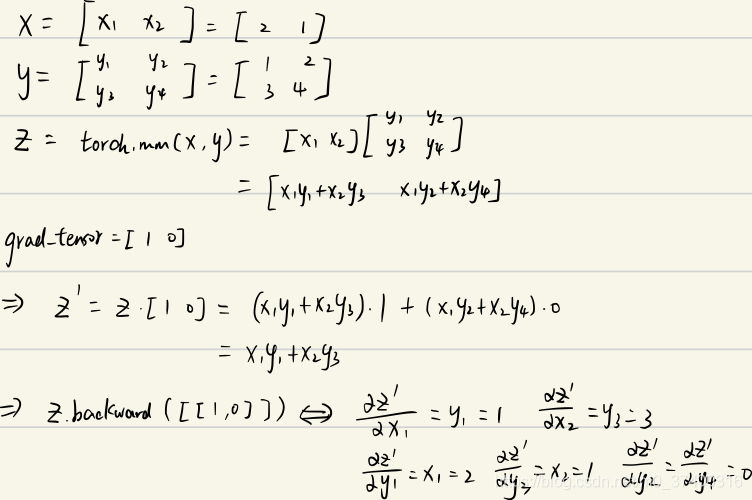
補充:PyTorch的計算圖和自動求導機制
自動求導機制簡介
PyTorch會根據(jù)計算過程自動生成動態(tài)圖����,然后根據(jù)動態(tài)圖的創(chuàng)建過程進行反向傳播��,計算每個節(jié)點的梯度值����。
為了能夠記錄張量的梯度�,首先需要在創(chuàng)建張量的時候設置一個參數(shù)requires_grad=True,意味著這個張量將會加入到計算圖中���,作為計算圖的葉子節(jié)點參與計算����,最后輸出根節(jié)點��。
對于PyTorch來說����,每個張量都有一個grad_fn方法,包含創(chuàng)建該張量的運算的導數(shù)信息��。在反向傳播的過程中��,通過傳入后一層的神經(jīng)網(wǎng)絡的梯度�,該函數(shù)會計算出參與運算的所有張量的梯度。
同時,PyTorch提供了一個專門用來做自動求導的包torch.autograd��。它包含兩個重要的函數(shù)�����,即torch.autograd.bakward和torch.autograd.grad�����。
torch.autograd.bakward通過傳入根節(jié)點的張量以及初始梯度張量���,可以計算產(chǎn)生該根節(jié)點的所有對應葉子節(jié)點的梯度。當張量為標量張量時��,可以不傳入梯度張量�����,這是默認會設置初始梯度張量為1.當計算梯度張量時��,原先建立起來的計算圖會被自動釋放��,如果需要再次做自動求導��,因為計算圖已經(jīng)不存在���,就會報錯�。如果要在反向傳播的時候保留計算圖,可以設置retain_graph=True���。
另外���,在自動求導的時候默認不會建立反向傳播的計算圖,如果需要在反向傳播的計算的同時建立梯度張量的計算圖����,可以設置create_graph=True。對于一個可求導的張量來說���,也可以調用該張量內部的backward方法����。
自動求導機制實例
定義一個函數(shù)f(x)=x2��,則它的導數(shù)f'(x)=2x�����。于是可以創(chuàng)建一個可導的張量來測試具體的導數(shù)。
t1 = torch.randn(3, 3, requires_grad=True) # 定義一個3×3的張量
print(t1)
t2 = t1.pow(2).sum() # 計算張量的所有分量的平方和
t2.backward() # 反向傳播
print(t1.grad) # 梯度是原始分量的2倍
t2 = t1.pow(2).sum() # 再次計算張量的所有分量的平方和
t2.backward() # 再次反向傳播
print(t1.grad) # 梯度累積
print(t1.grad.zero_()) # 單個張量清零梯度的方法
得到的結果:
tensor([[-1.8170, -1.4907, 0.4560],
[ 0.9244, 0.0798, -1.2246],
[ 1.7800, 0.0367, -2.5998]], requires_grad=True)
tensor([[-3.6340, -2.9814, 0.9120],
[ 1.8488, 0.1597, -2.4492],
[ 3.5600, 0.0735, -5.1996]])
tensor([[ -7.2681, -5.9628, 1.8239],
[ 3.6975, 0.3193, -4.8983],
[ 7.1201, 0.1469, -10.3992]])
tensor([[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]])
需要注意的一點是: 張量綁定的梯度張量在不清空的情況下會逐漸累積��。這在例如一次性求很多Mini-batch的累積梯度時是有用的���,但在一般情況下�,需要注意將張量的梯度清零����。
梯度函數(shù)的使用
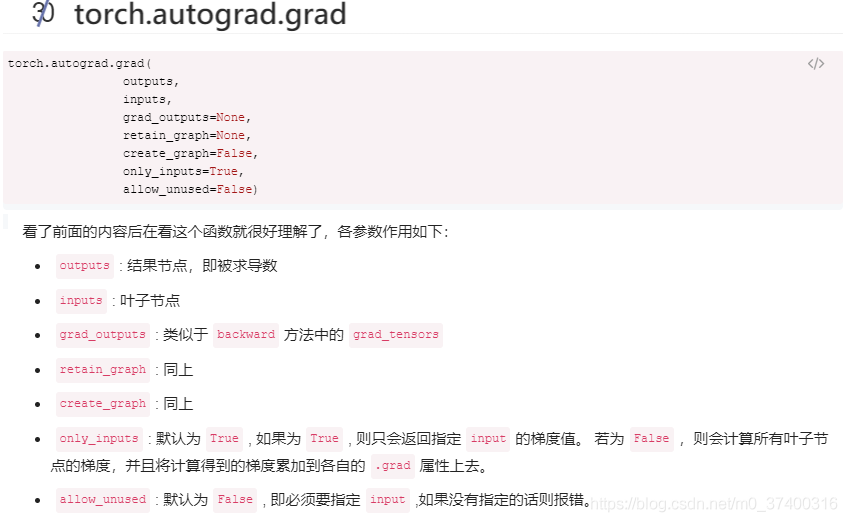
如果不需要求出當前張量對所有產(chǎn)生該張量的葉子節(jié)點的梯度,可以使用torch.autograd.grad函數(shù)����。
這個函數(shù)的參數(shù)是兩個張量,第一個張量是計算圖的張量列表���,第二個參數(shù)是需要對計算圖求導的張量。最后輸出的結果是第一個張量對第二個張量求導的結果�。
這個函數(shù)不會改變葉子節(jié)點的grad屬性,同樣該函數(shù)在反向傳播求導的時候釋放計算圖�,如果要保留計算圖需要設置retain_graph=True。
另外有時候會碰到一種情況:求到的兩個張量之間在計算圖上沒有關聯(lián)�。在這種情況下需要設置allow_unused=True,結果會返回分量全為0的梯度張量����。
t1 = torch.randn(3, 3, requires_grad=True)
print(t1)
t2 = t1.pow(2).sum()
print(torch.autograd.grad(t2, t1))
得到的結果為:
tensor([[ 0.5952, 0.1209, 0.5190],
[ 0.4602, -0.6943, -0.7853],
[-0.1460, -0.1406, -0.7081]], requires_grad=True)
(tensor([[ 1.1904, 0.2418, 1.0379],
[ 0.9204, -1.3885, -1.5706],
[-0.2919, -0.2812, -1.4161]])
計算圖構建的啟用和禁用
由于計算圖的構建需要消耗內存和計算資源���,在一些情況下計算圖并不是必要的,所以可以使用torch.no_grad這個上下文管理器��,對該管理器作用域中的神經(jīng)網(wǎng)絡計算不構建任何的計算圖�。
還有一種情況是對于一個張量,在反向傳播的時候可能不需要讓梯度通過這個張量的節(jié)點�����,也就是新建的計算圖需要和原來的計算圖分離����,使用張量的detach方法,可以返回一個新的張量��,該張量會成為一個新的計算圖的葉子結點��。
總結
PyTorch使用動態(tài)計算圖�,該計算圖的特點是靈活。雖然在構件計算圖的時候有性能開銷��,但PyTorch本身的優(yōu)化抵消了一部分開銷�����,盡可能讓計算圖的構建和釋放過程代價最小,因此�,相對于靜態(tài)圖的框架來說,PyTorch本身的運算速度并不慢����。
有了計算圖之后,就可以很方便地通過自動微分機制進行反向傳播的計算��,從而獲得計算圖葉子節(jié)點的梯度�����。在訓練深度學習模型的時候���,可以通過對損失函數(shù)的反向傳播����,計算所有參數(shù)的梯度����,隨后在優(yōu)化器中優(yōu)化這些梯度�����。
以上為個人經(jīng)驗,希望能給大家一個參考����,也希望大家多多支持腳本之家。
您可能感興趣的文章:- pytorch 中autograd.grad()函數(shù)的用法說明
- 淺談Pytorch中autograd的若干(踩坑)總結
- PyTorch一小時掌握之a(chǎn)utograd機制篇

